Resilient Networking: Planning for Failure
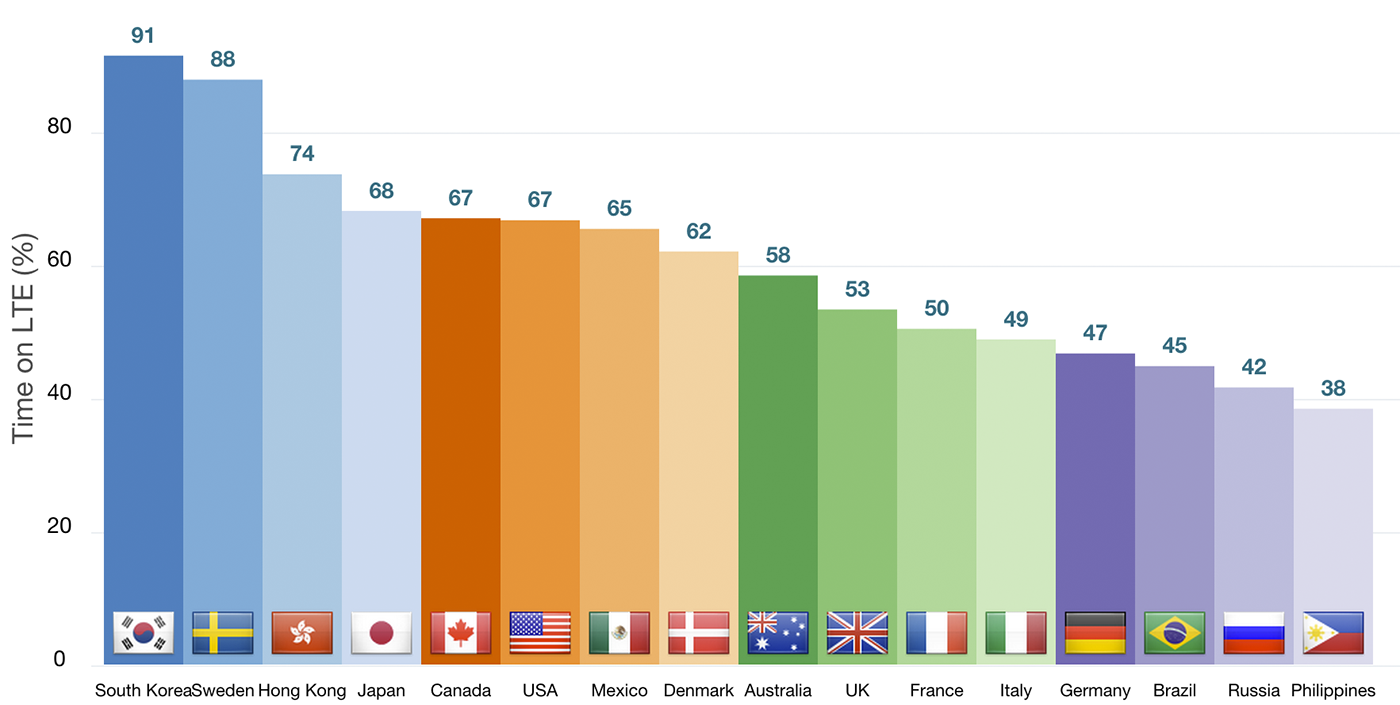
A 4G user will experience a much better median experience both in terms of bandwidth and latency than a 3G user, but the same 4G user will also fall back to the 3G network for some of the time due to coverage, capacity, or other reasons. Case in point, OpenSignal data shows that an average "4G user" in the US gets LTE service only ~67% of the time. In fact, in some cases the same "4G user" will even find themselves on 2G, or worse, with no service at all.
All connections are slow some of the time. All connections fail some of the time. All users experience these behaviors on their devices regardless of their carrier, geography, or underlying technology — 4G, 3G, or 2G.
You can use the OpenSignal Android app to track own stats for 4G/3G/2G time, plus many other metrics.
Why does this matter?
Networks are not reliable, latency is not zero, and bandwidth is not infinite. Most applications ignore these simple truths and design for the best-case scenario, which leads to broken experiences whenever the network deviates from its optimal case. We treat these cases as exceptions but in reality they are the norm.
- All 4G users are 3G users some of the time.
- All 3G users are 2G users some of the time.
- All 2G users are offline some of the time.
Building a product for a market dominated by 2G vs. 3G vs. 4G users might require an entirely different architecture and set of features. However, a 3G user is also a 2G user some of the time; a 4G user is both a 3G and a 2G user some of the time; all users are offline some of the time. A successful application is one that is resilient to fluctuations in network availability and performance: it can take advantage of the peak performance, but it plans for and continues to work when conditions degrade.
So what do we do?
Failing to plan for variability in network performance is planning to fail. Instead, we need to accept this condition as a normal operational case and design our applications accordingly. A simple, but effective strategy is to adopt a "Chaos Monkey approach" within our development cycle:
- Define an acceptable SLA for each network request
- Interactive requests should respect perceptual time constants.
- Background requests can take longer but should not be unbounded.
- Make failure the norm, instead of an exception
- Force offline mode for some periods of time.
- Force some fraction of requests to exceed the defined SLA.
- Deal with SLA failures instead of ignoring them.
Degraded network performance and offline are the norm not an exception. You can't bolt-on an offline mode, or add a "degraded network experience" after the fact, just as you can't add performance or security as an afterthought. To succeed, we need to design our applications with these constraints from the beginning.
Tooling and API's
Are you using a network proxy to emulate a slow network? That's a start, but it doesn't capture the real experience of your average user: a 4G user is fast most of the time and slow or offline some of the time. We need better tools that can emulate and force these behaviors when we develop our applications. Testing against localhost, where latency is zero and bandwidth is infinite, is a recipe for failure.
We need API's and frameworks that can facilitate and guide us to make the right design choices to account for variability in network performance. For the web, ServiceWorker is going to be a critical piece: it enables offline, and it allows full control over the request lifecycle, such as controlling SLA's, background updates, and more.
 Ilya Grigorik is a web ecosystem engineer, author of High Performance Browser Networking (O'Reilly), and Principal Engineer at Shopify — follow on Twitter.
Ilya Grigorik is a web ecosystem engineer, author of High Performance Browser Networking (O'Reilly), and Principal Engineer at Shopify — follow on Twitter.