Optimizing NGINX TLS Time To First Byte (TTTFB)
 Network latency is one of our primary performance bottlenecks on the web. In the worst case, new navigation requires a DNS lookup, TCP handshake, two roundtrips to negotiate the TLS tunnel, and finally a minimum of another roundtrip for the actual HTTP request and response — that's five network roundtrips to get the first few bytes of the HTML document!
Network latency is one of our primary performance bottlenecks on the web. In the worst case, new navigation requires a DNS lookup, TCP handshake, two roundtrips to negotiate the TLS tunnel, and finally a minimum of another roundtrip for the actual HTTP request and response — that's five network roundtrips to get the first few bytes of the HTML document!
Modern browsers try very hard to anticipate and predict user activity to hide some of this latency, but speculative optimization is not a panacea: sometimes the browser doesn't have enough information, at other times it might guess wrong. This is why optimizing Time To First Byte (TTFB), and TLS TTFB in particular due to the extra roundtrips, is critical for delivering a consistent and optimized web experience.
The why and the how of TTFB
According to the HTTP Archive, the size of the HTML document at 75th percentile is ~20KB+, which means that a new TCP connection will incur multiple roundtrips (due to slow-start) to download this file - with IW4, a 20KB file will take 3 extra roundtrips, and upgrading to IW10 will reduce that to 2 extra roundtrips.
To minimize the impact of the extra roundtrips all modern browsers tokenize and parse received HTML incrementally and without waiting for the full file to arrive. Stream processing enables the browser to discover other critical resources, such as references to CSS stylesheets, JavaScript, and other assets as quickly as possible and initiate those requests while waiting for the remainder of the document. As a result, optimizing your TTFB and the content of those first bytes can make a big difference to performance of your application:
- Don't buffer the entire response on the server. If you have partial content (e.g. page header), then flush it as early as possible to get the browser working on your behalf.
- Optimize the contents of the first bytes by including references to other critical assets as early as possible.
Measuring "out of the box" NGINX TLS TTFB
With the theory of TTFB out of the way, let's now turn to the practical matter of picking and tuning the server to deliver the best results. One would hope that the default “out of the box” experience for most servers would do a good job… unfortunately, that is not the case. Let's take a closer look nginx:
- Fresh Ubuntu server in ec2-west (micro instance) with nginx v1.4.4 (stable).
- The server is configured to serve a single 20KB (compressed) file.
- The TLS certificate is ~5KB and is using a 2048-bit key.
- The measurements are done with WebPageTest: 3G profile (300ms delay), Chrome (stable channel), Dulles location (~80ms actual RTT to the EC2 instance on the west coast).
The total client to server roundtrip time is ~380ms. As a result, we would expect a regular HTTP connection to yield a TTFB of ~1140ms: 380ms for DNS, 380ms for TCP handshake, and 380ms for the HTTP request and (instant) response. For HTTPS, we would add another two RTTs to negotiate all the required parameters: 1140ms + 760ms, or ~1900ms (5 RTTs) in total. Well, that's the theory, let's now try the theory in practice!

The HTTP TTFB is right on the mark (~1100ms), but what in the world is going on with HTTPS? The TTFB reported by WebPageTest shows ~2900ms, which is an entire extra second over our expected value! Is it the cost of the RSA handshake and symmetric crypto? Nope. Running openssl benchmarks on the server shows that it takes ~2.5ms for a 2048-bit handshake, and we can stream ~100MB/s through aes-256. It's time to dig deeper.
Fixing the “large” certificate bug in nginx
Looking at the tcpdump of our HTTPS session we see the ClientHello record followed by ServerHello response ~380ms later. So far so good, but then something peculiar happens: the server sends ~4KB of its certificate and pauses to wait for an ACK from the client - huh? The server is using a recent Linux kernel (3.11) and is configured by default with IW10, which allows it to send up to 10KB, what's going on?
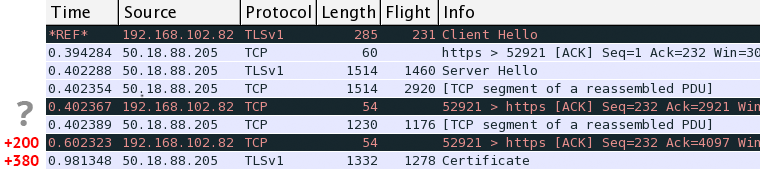
After digging through the nginx source code, one stumbles onto this gem. Turns out, any nginx version prior to 1.5.6 has this issue: certificates over 4KB in size incur an extra roundtrip, turning a two roundtrip handshake into a three roundtrip affair - yikes. Worse, in this particular case we trigger another unfortunate edge case in Windows TCP stack: the client ACKs the first few packets from the server, but then waits ~200ms before it triggers a delayed ACK for the last segment. In total, that results in extra 580ms of latency that we did not expect.
Ok, let's try the current mainline nginx release (1.5.7) and see if we fare any better...

Much better! After a simple upgrade the TLS TTFB is down to ~2300ms, which is about 600ms lower than our first attempt: we've just eliminated the extra RTT incurred by nginx and the ~200ms delayed ACK on the client. That said, we are not out of the woods yet — there is still an extra RTT in there.
Optimizing the TLS record size
TLS record size can have a significant impact on the page load time performance of your application. In this case, we run into this issue head first: nginx pumps data to the TLS layer, which in turn creates a 16KB record and then passes it to the TCP stack. So far so good, except that the server congestion window is less than 16KB for our new connection and we overflow the window, incurring an extra roundtrip while the data is buffered on the client. Fixing this requires making a quick patch to the nginx source:
diff nginx-1.5.7/src/event/ngx_event_openssl.c nginx-1.5.7-mtu/src/event/ngx_event_openssl.c
570c570
< (void) BIO_set_write_buffer_size(wbio, NGX_SSL_BUFSIZE);
---
> (void) BIO_set_write_buffer_size(wbio, 16384);
diff nginx-1.5.7/src/event/ngx_event_openssl.h nginx-1.5.7-mtu/src/event/ngx_event_openssl.h
107c107
< #define NGX_SSL_BUFSIZE 16384
---
> #define NGX_SSL_BUFSIZE 1400
After applying our two-line change and rebuilding the server our TTFB is down to ~1900ms — that's the 5 RTTs we expected at the start. In fact, it's easy to spot the difference from our previous run: the waterfall now shows the second RTT as content download time (blue section), whereas previously the browser couldn't process the HTML document until the very end. Success! But wait, what if I told you that we could do even better?
Enabling TLS False Start
TLS False Start allows us to eliminate an extra roundtrip of latency within the TLS handshake: the client can send its encrypted application data (i.e. HTTP request) immediately after it has sent its ChangeCipherSpec and Finished records, without waiting for the server to confirm its settings. So, how do we enable TLS False Start?
- Chrome will use TLS False Start if it detects support for NPN negotiation and forward secrecy — NPN is an independent feature, but the presence of NPN support is used to guard against broken implementations.
- Firefox toggled TLS False Start support multiple times, but it will be (re)enabled in M28, and will also require an NPN advertisement and support for forward secrecy.
- IE10+ uses a combination of blacklist and a timeout and doesn't require any additional TLS features.
- Apple landed TLS False Start support in OSX 10.9, which hopefully means that its coming to Safari.
In short, we need to enable NPN on the server, which in practice means that we need to rebuild nginx against OpenSSL 1.0.1a or higher — nothing more, nothing less. Let's do just that and see what happens...
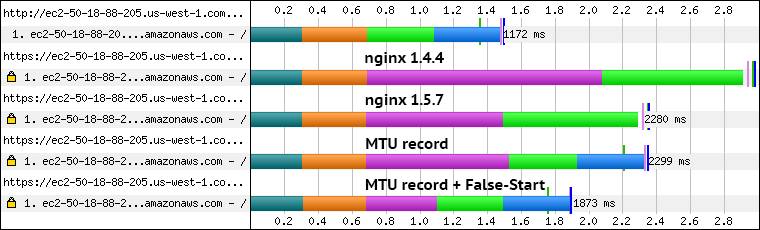
We started with a ~1800ms overhead for our TLS connection (nearly 5 extra RTTs); eliminated the extra certificate roundtrip after a nginx upgrade; cut another RTT by forcing a smaller record size; dropped an extra RTT from the TLS handshake thanks to TLS False Start. With all said and done, our TTTFB is down to ~1560ms, which is exactly one roundtrip higher than a regular HTTP connection. Now we're talking!
Yes, TLS does add latency and processing overhead. That said, TLS is an unoptimized frontier and we can mitigate many of its costs - it's worth it. Our quick exploration with nginx is a case in point, and most other TLS servers have all the same issues we've outlined above. Let's get this fixed. TLS is not slow, it's unoptimized.
 Ilya Grigorik is a web ecosystem engineer, author of High Performance Browser Networking (O'Reilly), and Principal Engineer at Shopify — follow on Twitter.
Ilya Grigorik is a web ecosystem engineer, author of High Performance Browser Networking (O'Reilly), and Principal Engineer at Shopify — follow on Twitter.