Weak Consistency and CAP Implications
 Migrating your web application from a single node to a distributed setup is always a deceivingly large architectural change. You may need to do it due to a resource constraint of a single machine, for better availability, to decouple components, or for a variety of other reasons. Under this new architecture, each node is on its own, and a network link is present to piece it all back together. So far so good, in fact, ideally we would also like for our new architecture to provide a few key properties: Consistency (no data conflicts), Availability (no single point of failure), and Partition tolerance (maintain availability and consistency in light of network problems).
Migrating your web application from a single node to a distributed setup is always a deceivingly large architectural change. You may need to do it due to a resource constraint of a single machine, for better availability, to decouple components, or for a variety of other reasons. Under this new architecture, each node is on its own, and a network link is present to piece it all back together. So far so good, in fact, ideally we would also like for our new architecture to provide a few key properties: Consistency (no data conflicts), Availability (no single point of failure), and Partition tolerance (maintain availability and consistency in light of network problems).
Problem is, the CAP theorem proposed by Eric Brewer and later proved by Seth Gilbert and Nancy Lynch, shows that together, these three requirements are impossible to achieve at the same time. In other words, in a distributed system with an unreliable communications channel, it is impossible to achieve consistency and availability at the same time in the case of a network partition. Alas, such is the tradeoff.
"Pick Two" is too simple
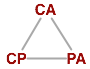 The original CAP conjecture presented by Eric Brewer states that as architects, we can only pick two properties (CA, CP, or PA) at the same time, and many attempts have since been made to classify different distributed architectures into these three categories. Problem is, as Daniel Abadi recently pointed out (and Eric Brewer agrees), the relationships between CA, CP and AP are not nearly as clear-cut as they appear on paper. In fact, any attempt to create a hard partitioning into these buckets seems to only increase the confusion since many of the systems can arbitrarily shift their properties with just a few operational tweaks - in the real world, it is rarely an all or nothing deal.
The original CAP conjecture presented by Eric Brewer states that as architects, we can only pick two properties (CA, CP, or PA) at the same time, and many attempts have since been made to classify different distributed architectures into these three categories. Problem is, as Daniel Abadi recently pointed out (and Eric Brewer agrees), the relationships between CA, CP and AP are not nearly as clear-cut as they appear on paper. In fact, any attempt to create a hard partitioning into these buckets seems to only increase the confusion since many of the systems can arbitrarily shift their properties with just a few operational tweaks - in the real world, it is rarely an all or nothing deal.
Focus on Consistency
Following some great conversations about CAP at a recent NoSQL Summer meetup and hours of trying to reconcile all the edge cases, it is clear that the CA vs. CP vs. PA model is, in fact, a poor representation of the implications of the CAP theorem - the simplicity of the model is nice, but in reality the actual design space requires more nuance. Specifically, instead of focusing on all three properties at once, it is more productive to first focus along the continuum of “data consistency” options: none, weak, and full.
 On one extreme, a system can demand no consistency. For example, a clickstream application which is used for best effort personalization can easily tolerate a few missed clicks. In fact, the data may even be partitioned by data centre, geography, or server, such that depending on where you are, a different “context” is applied - from home, your search returns one set of results, from work, another! The advantage of such a system is that it is inherently highly available (HA) as it is a share nothing, best effort architecture.
On one extreme, a system can demand no consistency. For example, a clickstream application which is used for best effort personalization can easily tolerate a few missed clicks. In fact, the data may even be partitioned by data centre, geography, or server, such that depending on where you are, a different “context” is applied - from home, your search returns one set of results, from work, another! The advantage of such a system is that it is inherently highly available (HA) as it is a share nothing, best effort architecture.
On the other extreme, a system can demand full consistency across all participating nodes, which implies some communications protocol to reach a consensus. A canonical example is a “debit / credit” scenario where full agreement across all nodes is required prior to any data write or read. In this scenario, all nodes maintain the exact same version of the data, but compromise HA in the process - if one node is down, or is in disagreement, the system is down.
CAP Implies Weak Consistency
Strong consistency and high availability are both desirable properties, however the CAP theorem shows that we can’t achieve both of these over an unreliable channel at once. Hence, CAP pushes us into a “weak consistency” model where dealing with failures is a fact of life. However, the good news is that we do have a gamut of possible strategies at our disposal.
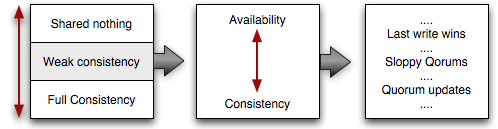
In case of a failure, your first choice could be to choose consistency over availability. In this scenario, if a quorum) can be reached, then one of the network partitions can remain available, while the second goes offline. Once the link between the two networks is restored, a simple data repair can take place - the minority partition is strictly behind, hence there are no possible data conflicts. Hence we sacrifice HA, but do continue to serve some of the clients.
On the other hand, we could lean towards availability over consistency. In this case, both sides can continue to accept reads and/or writes. Both sides of the partition remain available, and mechanisms such as vector clocks can be used to assist with conflict resolution (although, some conflicts will always require application level resolution). Repeatable reads, read-your-own-writes, and quorum updates are just a few of the examples of possible consistency vs. availability strategies in this scenario.
Hence, a simple corollary to the CAP theorem: when choosing availability under the weak consistency model, multiple versions of a data object will be present, will require conflict resolution, and it is up to your application to determine what is an acceptable consistency tradeoff and a resolution strategy for each type of object.
Speed of Light: Too Slow for PNUTS!
 Interestingly enough, dealing with network partitions is not the only case for adopting “weak consistency”. The PNUTS system deployed at Yahoo must deal with WAN replication of data between different continents, and unfortunately, the speed of light imposes some strict latency limits on the performance of such a system. In Yahoo’s case, the communications latency is enough of a performance barrier such that their system is configured, by default, to operate under the “choose availability, under weak consistency” model - think of latency as a pseudo-permanent network partition.
Interestingly enough, dealing with network partitions is not the only case for adopting “weak consistency”. The PNUTS system deployed at Yahoo must deal with WAN replication of data between different continents, and unfortunately, the speed of light imposes some strict latency limits on the performance of such a system. In Yahoo’s case, the communications latency is enough of a performance barrier such that their system is configured, by default, to operate under the “choose availability, under weak consistency” model - think of latency as a pseudo-permanent network partition.
Architecting for Weak Consistency
Instead of arguing over CA vs. CP vs. PA, first determine the consistency model for your application: strong, weak, or shared nothing / best effort. Notice that this choice has nothing to do with the underlying technology, and everything with the demands and the types of data processed by your application. From there, if you land in the weak-consistency model (and you most likely will, if you have a distributed architecture), start thinking how you can deal with the inevitable data conflicts: will you lean towards consistency and some partial downtime, or will you optimize for availability and conflict resolution?
Finally, if you are working under weak consistency, it is also worth noting that it is not a matter of picking just a single strategy. Depending on the context, the application layer can choose a different set of requirements for each data object! Systems such as Voldemort, Cassandra, and Dynamo) all provide mechanisms to specify a desired level of consistency for each individual read and write. So, an order processing function can fail if it fails to establish a quorum (consistency over availability), while at the same time, a new user comment can be accepted by the same data store (availability over consistency).
 Ilya Grigorik is a web ecosystem engineer, author of High Performance Browser Networking (O'Reilly), and Principal Engineer at Shopify — follow on Twitter.
Ilya Grigorik is a web ecosystem engineer, author of High Performance Browser Networking (O'Reilly), and Principal Engineer at Shopify — follow on Twitter.