Flow Analysis & Time-based Bloom Filters
 Working with large streams of data is becoming increasingly widespread, be it for log, user behavior, or raw firehose analysis of user generated content. There is some very interesting academic literature on this type of data crunching, although much of it is focused on query or network packet analysis and is often not directly applicable to the type of data we have to deal with in the social web. For example, if you were tasked to build (a better) "Trending Topics" algorithm for Twitter, how would you do it?
Working with large streams of data is becoming increasingly widespread, be it for log, user behavior, or raw firehose analysis of user generated content. There is some very interesting academic literature on this type of data crunching, although much of it is focused on query or network packet analysis and is often not directly applicable to the type of data we have to deal with in the social web. For example, if you were tasked to build (a better) "Trending Topics" algorithm for Twitter, how would you do it?
Of course, the challenge is that it has to be practical - it needs to be "real-time" and be able to react to emerging trends in under a minute, all the while using a reasonable amount of CPU and memory. Now, we don't know how the actual system is implemented at Twitter, nor will we look at any specific solutions - I have some ideas, but I am more curious to hear how you would approach it.
Instead, I want to revisit the concept of Bloom Filters, because as I am making my way through the literature, it is surprising how sparsely they are employed for these types of tasks. Specifically, a concept I have been thinking of prototyping for some time now: time-based, counting bloom filters!
Bloom Filters: What & Why
A Bloom Filter is a probabilistic data structure which can tell if an element is a member of a set. However, the reason it is interesting is because it accomplishes this task with an incredibly efficient use of memory: instead of storing a full hash map, it is simply a bit vector which guarantees that you may have some small fraction of false positives (the filter will report that a key is in the bloom filter when it is really not), but it will never report a false negative. File system and web caches frequently use bloom filters as the first query to avoid otherwise costly database or file system lookups. There is some math involved in determining the right parameters for your bloom filter, which you can read about in an earlier post.
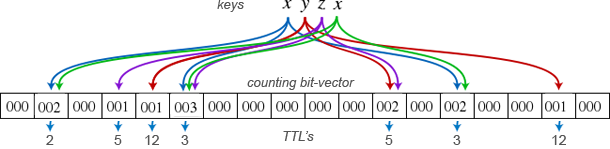
Of course, as is, the Bloom Filter data structure is not very useful for analyzing continuous data streams - eventually we would fill up the filter and it would begin reporting false positives all the time. But, what if your bloom filter only remembered seen data for a fixed interval of time? Imagine adding time-to-live (TTL) timestamp on each record. All of the sudden, if you knew the approximate number of messages for the interval of time you wanted to analyze, then a bloom filter is once again an incredibly fast and space-efficient (fixed memory footprint) data structure!
Time-based Bloom Filters
Arguably the key feature of bloom filters is their compact representation as a bit vector. By associating a timestamp with each record, the size of the filter immediately expands by an order of magnitude, but even with that, depending on the size of the time window you are analyzing, you could store the TTL's in just a few additional bits.
Conversely, if counting bits is not mission critical, you could even used a backend such as Redis or Memcached to drive the filter as well. The direct benefit of such approach is that the data can be shared by many distributed processes. On that note, I have added a prototype Redis backend to the bloomfilter gem which implements a time-based, counting Bloom Filter. Let's take a look at a simple example:
require 'bloomfilter'
options = {
:size => 100, # size of bit vector
:hashes => 4, # number of hash functions
:seed => rand(100), # seed value for the filter
:bucket => 3 # number of bits for the counting filter
}
# Regular, in-memory counting bloom filter
bf = BloomFilter.new(options)
bf.insert("mykey")
bf.include?("mykey") # => true
bf.include?("mykey1") # => false
#
# Redis-backed bloom filter, with optional time-based semantics
#
bf = BloomFilter.new(options.merge({:type => :redis, :ttl => 2, :server => {:host => 'localhost'}}))
bf.insert("mykey")
bf.include?("mykey") # => true
sleep(3)
bf.include?("mykey") # => false
# custom 5s TTL for a key
bf.insert("newkey", nil, 5)bloomfilter.git - Ruby+Redis counting Bloom Filter
Storing data in Redis or Memcached is roughly an order of magnitude less efficient, but it gives us an easy to use, distributed, and fixed memory filter for analyzing continuous data streams. In other words, a useful tool for applications such as duplicate detection, trends analysis, and many others.
Mechanics of Time-Based Bloom Filters
 So how does it work? Given the settings above, we create a fixed memory vector of 100 buckets (or bits in raw C implementation). Then, for each key, we hash it 4 times with different key offsets and increment the counts in those buckets - a non-negative value indicates that one of the hash functions for some key has used that bucket. Then, for a lookup, we reverse the operation: generate the 4 different hash keys and look them up, if all of them are non-zero then either we have seen this key or there has been a collision (false positive).
So how does it work? Given the settings above, we create a fixed memory vector of 100 buckets (or bits in raw C implementation). Then, for each key, we hash it 4 times with different key offsets and increment the counts in those buckets - a non-negative value indicates that one of the hash functions for some key has used that bucket. Then, for a lookup, we reverse the operation: generate the 4 different hash keys and look them up, if all of them are non-zero then either we have seen this key or there has been a collision (false positive).
By optimizing the size of the bit vector we can control the false positive rate - you're always trading the of amount of allocated memory vs. collision rate. Finally, we also make use of the native expire functionality in Redis to guarantee that keys are only stored for a bounded amount of time.
Time-based bloom filters have seen a few rogue mentions in the academic literature, but to the best of my knowledge, have not seen wide applications in the real world. However, it is an incredibly powerful data structure, and one that could benefit many modern, big-data applications. Gem install the bloomfilter gem and give it a try, perhaps it will help you build a better trends analysis tool. Speaking of which, what other tools, algorithms, or data structures would you use to build a "Trending Topics" algorithm for a high-velocity stream?
 Ilya Grigorik is a web ecosystem engineer, author of High Performance Browser Networking (O'Reilly), and Principal Engineer at Shopify — follow on Twitter.
Ilya Grigorik is a web ecosystem engineer, author of High Performance Browser Networking (O'Reilly), and Principal Engineer at Shopify — follow on Twitter.