Fibers & Cooperative Scheduling in Ruby
 Continuations have been a part of the Ruby API for quite some time, but for a variety of reasons have not seen much practical use: early Ruby 1.8 implementations suffered from serious memory leak problems, which were consequently mostly resolved, and the somewhat academic nature of the concept didn't help either. However, with the production versions of Ruby 1.9 out in the wild, continuations (now known as Fibers) deserve a second look.
Continuations have been a part of the Ruby API for quite some time, but for a variety of reasons have not seen much practical use: early Ruby 1.8 implementations suffered from serious memory leak problems, which were consequently mostly resolved, and the somewhat academic nature of the concept didn't help either. However, with the production versions of Ruby 1.9 out in the wild, continuations (now known as Fibers) deserve a second look.
Unlike a function, which has a defined entry and exit point, a continuation can return (yield) many times over, which means that the execution of a Fiber can be arbitrarily suspended and then resumed from the same point. While somewhat subtle, this is actually a very practical feature: continuations implicitly preserve state without having the programmer to worry about it.
Fiber Performance in Ruby
Continuations in Ruby 1.8 (MRI) suffered from a number of serious performance problems, but the introduction of Fibers in Ruby 1.9 warrants that we revisit the concept. First of all, Fibers are now cheaper to create and perform better than threads due to their nature as a lightweight context. And even better, they give us the ability to do cooperative scheduling - instead of using the preemptive context switch model we're all used to with threading, we can manually schedule Fibers to pass control back and forth whenever we want to.
Let's take a look at an admittedly contrived, but also a realistic scenario: two execution threads; one thread blocks for 40ms on an IO call and then takes 10ms to post-process the data; second thread needs 50ms of pure CPU time; vs same scenario implemented with Fibers and cooperative scheduling.
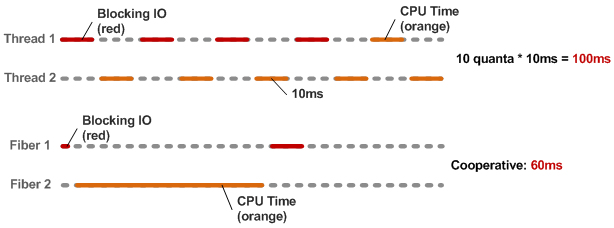
By default, Ruby MRI uses a fair scheduler, which means that each thread is given an equal time to run (10ms quantum) before it is suspended and the next thread is put in control. If one of your threads is inside a blocking call during those 10ms, think of it as time wasted - everyone is sleeping! By contrast, Fibers force the programmer to do explicit scheduling which can certainly add to the complexity of the program, but offer us the full flexibility of determining how our CPU resources are used and also help us avoid the need for locks in mutexes in our code!
Fibers and Cooperative IO Scheduling
Event-driven and asynchronous programming models are great candidates for application of Fibers. Ruby EventMachine allows us to asynchronously defer blocks of code to be executed when the resource (socket, file descriptor, etc) responds, which means that unlike a regular Net::HTTP call, we don't have to spin-wait indefinitely for the response. However, this model comes at a cost: it is often hard to retrofit code with asynchronous libraries because the callbacks have to be nested and the abstraction often breaks down (compare em-http-request to net/http API).
Fibers solve this problem for us by allowing us to turn an asynchronous library into what looks like a synchronous API without losing the advantages of IO-scheduling of the asynchronous execution:
require 'eventmachine'
require 'em-http'
require 'fiber'
def async_fetch(url)
f = Fiber.current
http = EventMachine::HttpRequest.new(url).get :timeout => 10
http.callback { f.resume(http) }
http.errback { f.resume(http) }
return Fiber.yield
end
EventMachine.run do
Fiber.new{
puts "Setting up HTTP request #1"
data = async_fetch('http://www.google.com/')
puts "Fetched page #1: #{data.response_header.status}"
EventMachine.stop
}.resume
end
# Setting up HTTP request #1
# Fetched page #1: 302Running the following code shows in-order output, which means that we've simulated a synchronous API while using an asynchronous library! Now imagine running multiple fibers in parallel while repeating this pattern: you will have interleaved execution which will be scheduled via IO interrupts - no extra context switches, no locks!
Joe Damato and Aman Gupta ported the functionality of Fibers to Ruby 1.8.(6|7), and also provide a great example of converting the asynchronous MySQL driver to work in synchronous fashion. Looking for more? Take a look at an implementation of Futures in Ruby and the Neverblock library.
Cooperative Scheduling: M Threads + N Fibers Model
While manual scheduling of Fibers may seem like a high cost, much of it can be abstracted into the underlying libraries and the potential benefits are enormous: cooperative scheduling is the optimal scheduling model and it does not incur the complexity inherent with threading. Having said that, there is still a place for threads!
Fibers will not give you concurrency on multi-core systems and they can only be resumed in the thread that created them. Hence, if we were aiming for the optimal resource utilization: run M threads, where M corresponds to number of cores, and optimize the number of Fibers (N) which can run within each thread. This way we can utilize all the available cores, and also take advantage of the IO scheduling model!
Fibers in JRuby, Rubinius and Other Applications
 Unlike the MRI Ruby VM, both JRuby and Rubinius implement "Poor Man's Fibers" where each Fiber is in fact, mapped to a native thread. This of course looses on the conceptual efficiency side when compared to MRI, but it still remains a viable and a more efficient option than the pure preemptive scheduling.
Unlike the MRI Ruby VM, both JRuby and Rubinius implement "Poor Man's Fibers" where each Fiber is in fact, mapped to a native thread. This of course looses on the conceptual efficiency side when compared to MRI, but it still remains a viable and a more efficient option than the pure preemptive scheduling.
In fact, while Fibers are great tool for abstracting asynchronous execution, they are also great for lazy evaluation patterns (such as Generators) and can even be used to add state/session persistence to the HTTP protocol! Wee is a Ruby continuations based web framework, which is likely inspired by some of Paul Grahams work at Viaweb (great read). Get Ruby 1.9 on your system, give Fibers a try!
 Ilya Grigorik is a web ecosystem engineer, author of High Performance Browser Networking (O'Reilly), and Principal Engineer at Shopify — follow on Twitter.
Ilya Grigorik is a web ecosystem engineer, author of High Performance Browser Networking (O'Reilly), and Principal Engineer at Shopify — follow on Twitter.