HTTP Archive + BigQuery = Web Performance Answers
 HTTP Archive is a treasure trove of web performance data. Launched in late 2010, the project crawls over 300,000 most popular sites twice a month and records how the web is built: number and types of resources, size of each resource, whether the resources are compressed or marked as cacheable, times to render the page, time to first paint, and so on - you get the point.
HTTP Archive is a treasure trove of web performance data. Launched in late 2010, the project crawls over 300,000 most popular sites twice a month and records how the web is built: number and types of resources, size of each resource, whether the resources are compressed or marked as cacheable, times to render the page, time to first paint, and so on - you get the point.
The HTTP Archive site itself provides a number interesting stats and aggregate trends, but the data on the site only scratches the surface of the kinds of questions you can ask! To satisfy your curiousity, all you need to do is download and import ~400GB of raw SQL/CSV data. Easy, right? Yeah, not really. Instead, wouldn't it be nice if we had the full dataset of all the HTTP Archive data to query on demand, and with ad-hoc questions?
Google BigQuery + HTTP Archive
Well, good news, now you can satisfy your curiosity in minutes (or seconds, even). The full HTTP Archive dataset is now available on BigQuery! To get started, signup for BigQuery and head to bigquery.cloud.google.com and click the down arrow beside "API Project": Switch to project > Display project > enter "httparchive"
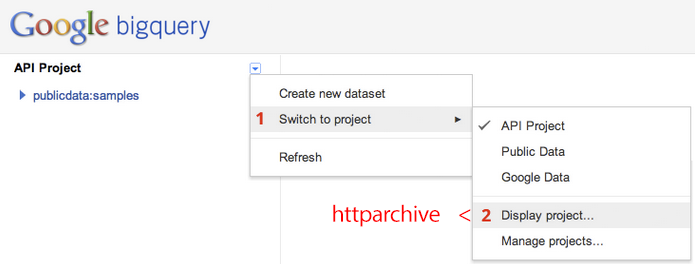
Once the project is imported, expand the project in left navigation and you'll see a collection of tables for individual pages and request data for each run of the HTTP Archive crawler. From there, pull up the SQL console, and go nuts! For example, let's start simple: what is the median time to first render?
SELECT
NTH(50, quantiles(renderStart,100)) median,
NTH(75, quantiles(renderStart,100)) seventy_fifth,
NTH(90, quantiles(renderStart,100)) ninetieth
FROM [httparchive:runs.2013_06_01_pages]And the answer is: 2.2s median, 3.3s for 75th percentile, and 4.7s for 90th percentile. BigQuery provides a number of convenience functions, such as quantiles, statistical approximations, extended regular expression matching and extraction, and a lot more. Check out the query reference and query cookbook to learn more.
One JS framework is not enough!
To flex our new BigQuery muscle let's find pages which use multiple JavaScript frameworks on same page:
SELECT pages.pageid, url, cnt, libs, pages.rank rank FROM [httparchive:runs.2013_06_01_pages] as pages JOIN (
SELECT pageid, count(distinct(type)) cnt, GROUP_CONCAT(type) libs FROM (
SELECT REGEXP_EXTRACT(url,
r'(jquery|dojo|angular|prototype|backbone|emberjs|sencha|scriptaculous).*\.js') type, pageid
FROM [httparchive:runs.2013_06_01_requests]
WHERE REGEXP_MATCH(url, r'jquery|dojo|angular|prototype|backbone|emberjs|sencha|scriptaculous.*\.js')
GROUP BY pageid, type
)
GROUP BY pageid
HAVING cnt >= 2
) as lib ON lib.pageid = pages.pageid
WHERE rank IS NOT NULL
ORDER BY rank asc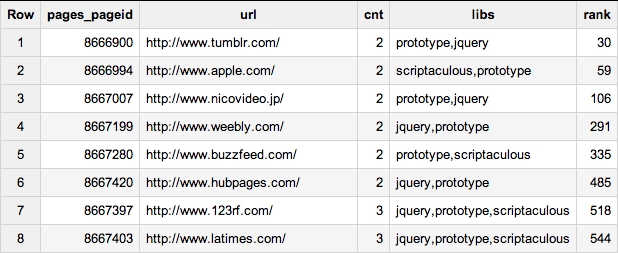
JQuery is the clear crowd favorite, but prototype (despite its age) is holding strong. Worse, there are many sites with three or four different frameworks, and even different versions of each one on the same page!
Happy dremeling - err, BigQuerying! For more examples, check out this gist with sample queries.
 Ilya Grigorik is a web ecosystem engineer, author of High Performance Browser Networking (O'Reilly), and Principal Engineer at Shopify — follow on Twitter.
Ilya Grigorik is a web ecosystem engineer, author of High Performance Browser Networking (O'Reilly), and Principal Engineer at Shopify — follow on Twitter.