Deploying New Image Formats on the Web
 An average page is now over 1200kB in size and 60% of that is in images. With all the focus on performance and speed across the web performance industry, you would think that innovating on better image formats would be a top agenda item. Not so. Instead, we are living in a self-imposed world of scarcity of formats, effectively limiting ourselves to gif’s, png’s and jpeg’s.
An average page is now over 1200kB in size and 60% of that is in images. With all the focus on performance and speed across the web performance industry, you would think that innovating on better image formats would be a top agenda item. Not so. Instead, we are living in a self-imposed world of scarcity of formats, effectively limiting ourselves to gif’s, png’s and jpeg’s.
In practice, deploying new image formats has been painful - just think back to the saga of png. But one would also hope that png was not the last. In fact, if we really want to make an impact on web performance, then image formats is the place to do it. There is absolutely no reason why we shouldn't have dozens of specialized formats, each tailored for a specific case and type of image. But before we get there, we need to iron out some kinks...
Deploying new "Magic Image Format"
As a practical example, let's imagine we have just invented a new magic image format (mif). How do we deploy it? As a recent bug on W3C points out, our markup provides no facility to specify different formats for a single image. Let's assume we add such a mechanism. The syntax does not matter, I'll just make it up for the sake of an example:
<img srcset="awesome.jpeg 1x, awesome.mif 2x" alt="Use awesome MIF for retina screens!">So far, so good. The browser reads the page and decides to load the .mif file while rendering the page. The user loves our awesome image and decides to share it on their favorite social network: right click, copy URL, or simply drags the image into a bookmarklet or extension. At this point, we have a problem. Our user's friends may use a different browser, which may not support .mif files. Instead of an awesome image, they see a broken asset.
Why did this occur? When presented with all the available image options, the browser was able to negotiate the format for the user, but then the user made the singular choice for all of his friends, and in the process broke it for them. Client-driven negotiation breaks down the moment the resource leaves the page where all of the representations are available.
Now, in theory, the browsers could address this by ensuring that every time you grab the asset URL, either via drag and drop, right click, or even JavaScript interaction, then a "safe" URL is returned. However, in the long run, I don't think this is the right solution.
Humans don't scale
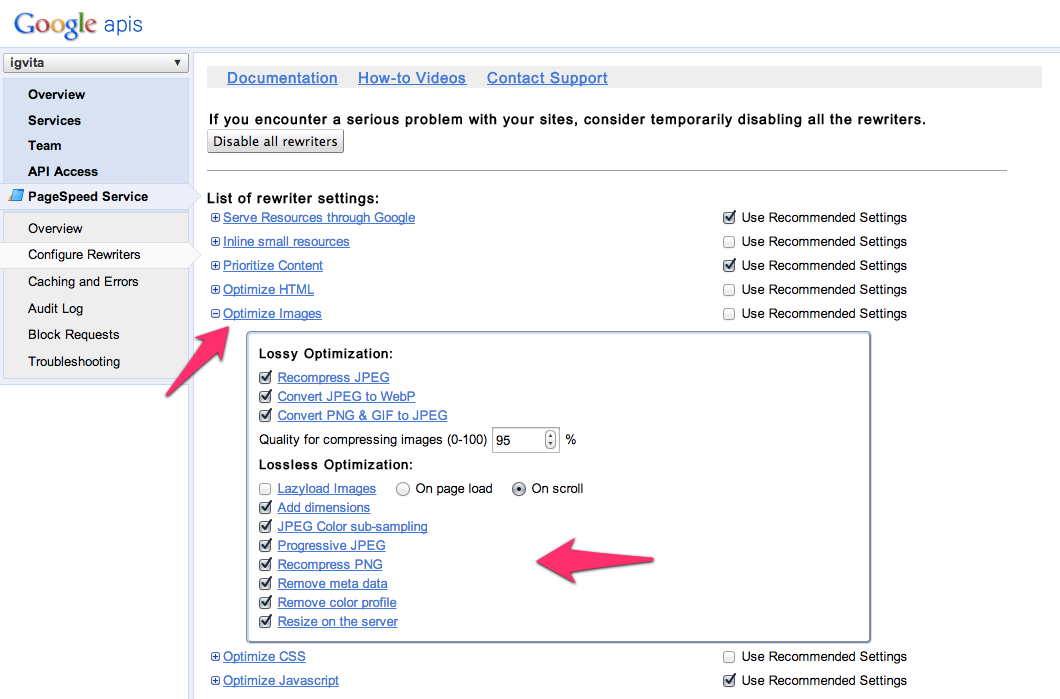
 Quick, what is the format for the image on the left? Trick question. The file is saved as a
Quick, what is the format for the image on the left? Trick question. The file is saved as a .png on my origin server, but depending on your browser, it's either coming up as a .jpeg, or a .webp as you're viewing this page. PageSpeed Service proxy tested the various formats, and decided to re-encode the image to achieve better compression (see settings).
{kind=link}
{kind=link}
In fact, we already know, based on empirical results, that we as humans are terrible at optimizing images: we forget to resize them, we pick the wrong formats, and its tedious work. You would think that with three image formats to choose from, such problems would not exist. Not so. I've long stopped worrying about hand-optimizing images. Computers are much better at this task than we are, and they also don't mind the boring work.
The format doesn't actually matter
For the sake of an argument, let's say we do hand-optimize each image asset. Next, enumerate each variant:
<img srcset="path/awesome.jpeg, path/awesome.png, path/awesome.webp,
path/awesome.svg, path/awesome.mif, path/awesome.mif2"
alt="How many times do I need to repeat myself?">That is silly, boring, and a waste of bytes in the markup. We'll need automation tools just to simplify the task of generating the repeated boilerplate - not unlike the existing CSS prefix woes. So, with that, the extension of the image file doesn't actually matter - we can do without it.
Let's imagine that we instead invent an abstract .img format, which acts as a stand-in for the optimal format. What is optimal? It is a function of the image contents and the user agent preference and capabilities at the time of the request. Who performs the optimization? The server, of course. Given a single source image, it is able to re-encode, recompress, resize, strip unnecessary metadata, ..., and deliver the optimal format.
In a world with dozens of image formats, the human solution does not scale - read, markup does not scale. Whereas computers are fantastic at doing exactly the kind of optimization work required to solve the problem.
Content-type negotiation
Good news, HTTP 1.1 already anticipated all of the mechanics to make this work with server-driven negotiation:
- User agent indicates which file types it supports or is willing to accept through
Acceptrequest header - Server selects the format and indicates the returned type through
Content-Typeresponse header
Note that the extension on the image file in the URL does not matter. The same URL can return a different representation based on the negotiated client-server preferences, and the browser then uses the Content-Type to properly interpret the response. No need for extra markup, no need to hand-tune each image. Further, users don't care which format is negotiated, as long as the image works, and as long as it is delivered quickly.
Outlines of the solution
If content negotiation is already here, then why are we even having this discussion? On paper we have all we need, in practice, there are a few implementation issues to resolve. First, let's look at the Accept headers sent by modern browsers when making a request for an image resource:
| Chrome | */* |
| Safari | */* |
| Firefox | image/png,image/*;q=0.8,*/*;q=0.5 |
| Internet Explorer | image/png,image/svg+xml,image/*;q=0.8, */*;q=0.5 |
| Opera | text/html, application/xml;q=0.9, application/xhtml+xml, image/png, image/webp, image/jpeg, image/gif, image/x-xbitmap, */*;q=0.1 |
Chrome and Safari headers are effectively useless - we accept everything! Firefox and IE aren't doing much better. Opera is the only one explicitly enumerating the supported filetypes, which is the behavior we want, albeit it also adds some unnecessary types at the front. If we want server-driven negotiation to work, then the first task is to get the browsers to send a useful Accept header - a header which actually enumerates the supported types.
However, fixing the Accept header is only half the problem. The fact that the same URL may have multiple representations means that all the intermediate caches must have a way to differentiate the various responses. Thankfully, HTTP 1.1 has a mechanism for that as well, the Vary header.
(client) > Accept: image/jpeg, image/png, image/mif
(server) > Content-Type: image/mif
> Vary: Accept
> (object)The server indicates to upstream clients that the resource should be varied based on the value of client's Accept header by returning Vary: Accept. In the example above, given the choice of three formats, the server chose mif as the optimal one. Any upstream cache can safely cache and serve the mif object to any user agent which provides the the same Accept header. If another user agent sends a different header value, for example without image/mif, then a different format will be served and cached. To the user, this negotiation is transparent.
But, but, but...
 But this puts more header bytes on the wire! Yes, it does. If we explicitly enumerate all image types, then the header is 50-100 bytes in the upstream. Half of the requests (~40) on an average page are image requests, which means ~2~4kB in total. In the downlink, these images cost us ~600kB. Assuming we can get 10-30% better compression - a realistic number for WebP, as we'll see below - this translates to 60-180kB in savings, and a 30-45x return on investment. And
But this puts more header bytes on the wire! Yes, it does. If we explicitly enumerate all image types, then the header is 50-100 bytes in the upstream. Half of the requests (~40) on an average page are image requests, which means ~2~4kB in total. In the downlink, these images cost us ~600kB. Assuming we can get 10-30% better compression - a realistic number for WebP, as we'll see below - this translates to 60-180kB in savings, and a 30-45x return on investment. And I hope I know we can do even better in the future.
Further, for HTTP 2.0, we will have header compression, which will amortize the cost of sending the image header down to a single transfer of 50-100 bytes, instead of the ~2~4kB in current overhead. As for HTTP 1.1, we can be smart and provide a site controlled opt-in mechanism, such that only sites which support the new negotiation will get the updated header from the browser - the mechanics of this deserves its own separate discussion.
But this would fragment the cache! Small changes in the Accept header could potentially create duplicate entries in the cache. This is nothing new, and the spec documents ways to normalize the headers: downcase, order does not matter, etc. Also, "Key" proposal is specifically designed to resolve this issue in a generic, cache-friendly way.
But cache support for Vary is missing! Turns out, most CDN's will simply not cache anything with Vary: Accept. That's a sad state of affairs and should be considered a bug. The good news is, this is not rocket science, rather it is a question of business incentives. Better image optimization translates to fewer bytes on the wire and better performance - this is aligned with what every CDN is trying to sell you. If the client support is there, then support for Vary: Accept is a competitive edge for every cache and CDN provider.
But old clients will break with Vary: Accept! Support for Vary has been spotty in older clients: IE6 won't cache any asset with Vary, IE7 will cache but makes a conditional request, and so on. One practical approach is to make this a forward looking optimization where only newer clients would trigger the new behavior.
But now I need new server software to optimize the images! Yes, you will. This is once again a question of incentives for hosting providers and CDN's. In fact, many CDN's already perform image optimization at the edge. Similarly, open-source projects like mod_pagespeed and ngx_pagespeed are drop-in modules, which will do all the work required to make this work.
But this means more load on the server! Dynamic image optimization doesn't come for free, but your time is more valuable. The server can optimize the asset, cache it, and be done with it. There is no global shortage of CPU cycles, and once there is an incentive, these image optimization workflows will be tuned into oblivion.
Hands on example with WebP
WebP is a new image format that provides lossless and lossy compression for images on the web. WebP lossless images are 26% smaller in size compared to PNGs. WebP lossy images are 25-34% smaller in size compared to JPEG images at equivalent SSIM index. WebP supports lossless transparency (also known as alpha channel) with just 22% additional bytes. Transparency is also supported with lossy compression and typically provides 3x smaller file sizes compared to PNG when lossy compression is acceptable for the red/green/blue color channels.
25-35% savings over PNG and JPEG, and up to 60%+ for PNG’s with an alpha (transparency) channel. That's hundreds of kilobytes of savings on most every page. Something worth fighting for.
![]() Both Chrome and Opera support WebP, as do some optimization proxies such as mod_pagespeed, PageSpeed Service, Torbit, and few others. However, because of the lacking context in existing
Both Chrome and Opera support WebP, as do some optimization proxies such as mod_pagespeed, PageSpeed Service, Torbit, and few others. However, because of the lacking context in existing Accept headers, each is forced to mark .webp resources with a Cache-Control: private header. This effectively forces every request to be routed to the optimizing proxy, which then performs user agent detection and serves the appropriate content type.
As many have pointed out, this method does not scale: every request is routed to the origin server, and marking the resource as private bypasses all the intermediate caches. This alone is enough of a reason for why we haven’t seen WebP, and other experimental formats, get any significant adoption on the modern web.
The "action plan"
Step one, we need to fix and normalize the Accept headers. Opera's header is the closest to what we want, albeit we can restrict the content-types for image assets when requesting an image resource. Perhaps something like:
Accept: image/webp, image/png, image/jpeg, image/gif, image/svg+xml, image/bitmapWith that in place, there is an incentive for the CDNs, proxies, and servers to perform the negotiation to deliver the optimal image format. Finally, once the server can choose the format, the upstream caches have an incentive to make Vary work. In the end, we shave off hundreds of kilobytes of image data, we automate the menial task of selecting the optimal image formats, and we have a future-proof negotiation mechanism which can scale to dozens of image formats. Everyone wins... until we offset the win by embedding more cat pictures on our pages...
 Ilya Grigorik is a web ecosystem engineer, author of High Performance Browser Networking (O'Reilly), and Principal Engineer at Shopify — follow on Twitter.
Ilya Grigorik is a web ecosystem engineer, author of High Performance Browser Networking (O'Reilly), and Principal Engineer at Shopify — follow on Twitter.