Stream(SQL) Event Processing with Esper
 The growth of both the types and the amount of data generated by servers, users, and applications have resulted in a number of recent trends and innovations: NoSQL, rise of popularity of Hadoop, and dozens of higher-level map-reduce frameworks. However, the batch-processing model imposed by map-reduce style of processing is not always a great fit either, especially if latency is a priority.
The growth of both the types and the amount of data generated by servers, users, and applications have resulted in a number of recent trends and innovations: NoSQL, rise of popularity of Hadoop, and dozens of higher-level map-reduce frameworks. However, the batch-processing model imposed by map-reduce style of processing is not always a great fit either, especially if latency is a priority.
What if we turn the problem on its head: instead of storing data and then executing batch queries over it, what if we persisted the query and ran the data through it? That is the core idea and insight behind Event Stream Processing (ESP) systems: store queries not data, process each event in real-time, and emit results when some query criteria is met. This is a model that has been well explored in the financial sector (ex: analyzing stock data feeds), and has scaled extremely well - perhaps a pattern we could learn from.
Stream Event Processing with StreamSQL
SQL has proven to be a great language because it defines a small set of powerful data processing primitives: filter, merge, and aggregate. However, SQL was also defined to work on finite-size sets of records, whereas our problem is that of analyzing a continuous stream of data - not going to work. It is not hard to imagine how one could implement a filter or merge operation in your own language of choice (a route many have taken), but as it turns out, we don't have to throw out SQL just yet, we just need to extend it with some new primitives.
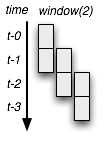 There is no official standard for "StreamSQL", and each vendor has their own take on the problem, but most agree on the basics: events (usually timestamped) serve as input, an engine evaluates each event with respect to the specified queries, and the SQL syntax is extended with base primitives such as ticks, timers, and windows.
There is no official standard for "StreamSQL", and each vendor has their own take on the problem, but most agree on the basics: events (usually timestamped) serve as input, an engine evaluates each event with respect to the specified queries, and the SQL syntax is extended with base primitives such as ticks, timers, and windows.
A window in StreamSQL can be defined as a period of time, ticks, or events flowing through the engine. Only the simplest queries can be answered by analyzing each event individually (ex: finding a global min or max number in a continuous stream), and hence a certain amount of data must be kept around (ex: find average price over last 60s). How the data is persisted (or not) is up to the engine, but the key is that the window is bounded and is updated incrementally as new events are registered.
ESP with Esper
Going from abstract to more concrete, Esper is an open-source ESP and correlation engine which definitely deserves some attention. Started in 2004 by Thomas Bernhardt for a financial application, it is implemented in Java and provides a fully featured, fast ESP library with a powerful list of StreamSQL extensions. Esper keeps all data structures in memory (no external database required) and is multi-thread safe and able to make use of all the available CPUs. A code example is worth a thousand words:
# full gist: https://gist.github.com/994739
class TweetListener
include UpdateListener
def update(newEvents, oldEvents)
newEvents.each do |event|
puts "New event: #{event.getUnderlying.toString}"
end
end
end
epService = EPServiceProviderManager.getDefaultProvider
statement = epService.getEPAdministrator.createEPL("SELECT * from TweetEvent")
statement.addListener(TweetListener.new)
TweetStream::Client.new('username','password').track('keyword') do |t|
event = TweetEvent.new(t.user.screen_name, t.text, t.user.time_zone, t.retweet_count)
epService.getEPRuntime.sendEvent(event);
endA little help from JRuby (see full gist) and we are up and running: we are connecting to a push Twitter search stream, creating simple TwitterEvent objects for each new tweet and pushing them into Esper. Right above, we have also defined a simple "select all" StreamSQL query and provided a listener, which is invoked with the results. TweetEvents are regular Java objects (POJO's), and our Listener class implements the UpdateListener interface - that's it.
Run the example above, and not surprisingly, you will see Esper invoke our listener with every tweet we push into it. Not very exciting, but now lets see what else we can do with StreamSQL:
# find the sum of retweets of last 5 tweets which saw more than 10 retweets
SELECT sum(retweets) from TweetEvent(retweets >= 10).win:length(5)
# find max, min and average number of retweets for a sliding 60 second window of time
SELECT max(retweets), min(retweets), avg(retweets) FROM TweetEvent.win:time(60 sec)
# compute number of retweets for all tweets in 10 second batches
SELECT sum(retweets) from TweetEvent.win:time_batch(10 sec)
# number of retweets, grouped by timezone, buffered in 10 second increments
SELECT timezone, sum(retweets) from TweetEvent.win:time_batch(10 sec) group by timezone
# compute the sum of retweets in sliding 60 second window, and emit count every 30 events
SELECT sum(retweets) from TweetEvent.win:time(60 sec) output snapshot every 30 events
# every 10 seconds, report timezones which accumulated more than 10 retweets
SELECT timezone, sum(retweets) from TweetEvent.win:time_batch(10 sec) group by timezone having sum(retweets) > 10
# Example output with our Listener class:
# ["{timezone=null, sum(retweets)=101}"]
# ["{timezone=Caracas, sum(retweets)=17}"]
# ["{timezone=Central Time (US & Canada), sum(retweets)=15}"]No glue code, no custom data handlers, and yet we are able to easily apply filters, aggregations, and much more! In fact, the above examples only scratch the surface of what is possible - check the EPL documentation for more. Esper automatically maintains only the data we need to fulfill our queries and expires old events as new ones arrive - nice.
Joins, Correlations and Complex Event Processing
Having a powerful framework for manipulating a data stream is liberating, but it only gets more interesting when we are able to join multiple streams: why not intersect clickstream data, site activity data, and log data to optimize a recommendations system, or to detect fraud? Esper allows you to do exactly that, in real-time. We can feed multiple data streams into the engine, join and intersect the data, define new views based on these results, detect correlations, and much more.
Hadoop and map-reduce batch processing is a popular way to answer some of the similar questions today, but that model imposes a large and an often unnecessary latency barrier. Stream processing, with time window semantics and fixed memory footprint can be a much more agile, faster and cheaper way to get at the same answers.
 Ilya Grigorik is a web ecosystem engineer, author of High Performance Browser Networking (O'Reilly), and Principal Engineer at Shopify — follow on Twitter.
Ilya Grigorik is a web ecosystem engineer, author of High Performance Browser Networking (O'Reilly), and Principal Engineer at Shopify — follow on Twitter.