Life beyond HTTP 1.1: Google's SPDY
 Tim Berners-Lee rightfully deserves all the credit for his early work around URI, HTTP and HTML. His efforts ultimately led to the official HTTP 1.0 (RFC 1945) specification in 1996, the HTTP 1.1 proposal (RFC 2068) in 1997 and consequently the official HTTP 1.1 spec (RFC 2616) in 1999. The web as we know it wouldn't exist without these protocols.
Tim Berners-Lee rightfully deserves all the credit for his early work around URI, HTTP and HTML. His efforts ultimately led to the official HTTP 1.0 (RFC 1945) specification in 1996, the HTTP 1.1 proposal (RFC 2068) in 1997 and consequently the official HTTP 1.1 spec (RFC 2616) in 1999. The web as we know it wouldn't exist without these protocols.
However, more then a decade has passed, we now have billions of users online, our web apps have grown by orders of magnitude in both size and complexity, and the HTTP specification is starting to show its age. Google's Chrome browser dropped the "http://" prefix in their location bar about a year ago, and as it turns out, not just for aesthetic reasons: if you are using Chrome, and you are using Google web services today, chances are, you are not running over HTTP! Let that sink in for a minute. More likely, your browser is using SPDY - let's dig in.
Evolution HTTP and Latency
As we focus on making our web-apps being first class citizens in our everyday workflow, latency immediately surfaces as the primarily hurdle. Unfortunately, this is also the weak spot for HTTP. The original HTTP 1.0 spec mandated that the connection to the server should be closed after every single request/response cycle: no connection reuse, and an implicit TCP setup and teardown between each request - an expensive pattern.
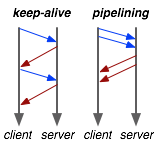 Some of the major changes in HTTP 1.1 were to address exactly this issue: RFC 2616 defaulted to "keep alive" connections and introduced "pipelining". Keep-alive allows us to reuse the same underlying TCP connection between requests, and pipelining promised us to remove the strict "one at a time" requirement. Both sensible changes, but unfortunately, while keep-alive has found its way into most clients and servers, pipelining is disabled in all but one browser (Opera) to this day.
Some of the major changes in HTTP 1.1 were to address exactly this issue: RFC 2616 defaulted to "keep alive" connections and introduced "pipelining". Keep-alive allows us to reuse the same underlying TCP connection between requests, and pipelining promised us to remove the strict "one at a time" requirement. Both sensible changes, but unfortunately, while keep-alive has found its way into most clients and servers, pipelining is disabled in all but one browser (Opera) to this day.
However, even if we manage to deploy pipelining support, there is still an unresolved issue: HTTP forces strict FIFO semantics for all the requests. Have a slow dynamic request at the front of the queue? Everyone else sharing that TCP channel will have to wait until it completes.
SPDY: Life beyond HTTP 1.1
SPDY (SPeeDY) is a Google research project and an application-level protocol for transporting web content. The primary goal of SPDY is to reduce latency, which is a promise on which it delivers: head to head tests against HTTP show SPDY with up to 64% reduction in page load times! Same pages, same TCP pipe, different protocol - nice win.
 High level summary of SPDY changes and features: true request pipelining without FIFO restrictions, message framing mechanism to simplify client and server development, mandatory compression (including headers), priority scheduling, and even bi-directional communication! Let's dig into these a bit more.
High level summary of SPDY changes and features: true request pipelining without FIFO restrictions, message framing mechanism to simplify client and server development, mandatory compression (including headers), priority scheduling, and even bi-directional communication! Let's dig into these a bit more.
Unlike HTTP, each request in SPDY is assigned a "stream ID", which allows us to use a single TCP channel to send data between the client and the server in parallel: we can serve multiple resources at the same time through the same channel by simply identifying which stream the data belongs to. To support this, SPDY defines a simple to parse binary protocol with two types of "frames": control, and data.
Turns out, while HTTP payloads can be compressed, the HTTP headers always currently travel as plain-text over the wire. SPDY compresses all header meta data with a predefined dictionary. Likewise, since SPDY now supports true pipelining, it also allows us to assign request priorities to each resource (ex: HTML first, JS second). Finally, why have the browser initiate all the requests? After all, if the server knows which page you are fetching, then it can "hint" to the client which images it may need before the client even parses that HTML - server push!
SPDY in the wild
Turns out, while the original work and tests around SPDY were done in the Chromium project, since then, the official Google Chrome client has shipped with built-in SPDY support, and not surprisingly, Google's servers are also SPDY enabled. In other words, if you use Chrome, and you're using Google services, then many of those pages are not arriving to you over HTTP - you are actually running over SPDY!
Curious to try SPDY in your own stack? Check out the available Apache plugin (mod-spdy), the Python server/client implementation, or the spdy ruby gem. The Ruby parser is a work in progress, but it does provide a way to parse the incoming data, and will also help you craft a server response for your SPDY client (see the hello world example):
require 'spdy'
s = SPDY::Parser.new
s.on_headers_complete { |stream_id, associated_stream, priority, headers| ... }
s.on_body { |stream_id, data| ... }
s.on_message_complete { |stream_id| ... }
s << recieved_dataspdy.git - Ruby SPDY protocol parser
The road to HTTP 2.0, or beyond!
Given all the benefits that SPDY offers, it is surprising how little attention it has received since its release. Google has also been fairly quiet about it since the initial announcement - low latency web services are a big competitive advantage, perhaps they have a reason to be quiet? Regardless, it is an open protocol, and one worth investigating.
 Ilya Grigorik is a web ecosystem engineer, author of High Performance Browser Networking (O'Reilly), and Principal Engineer at Shopify — follow on Twitter.
Ilya Grigorik is a web ecosystem engineer, author of High Performance Browser Networking (O'Reilly), and Principal Engineer at Shopify — follow on Twitter.