Multi-core, Threads & Message Passing
 Moore's Law marches on, the transistor counts are continuing to increase at the predicted rate and will continue to do so for the foreseeable future. However, what has changed is where these transistors are going: instead of a single core, they are appearing in multi-core designs, which place a much higher premium on hardware and software parallelism. This is hardly news, I know. However, before we get back to arguing about the "correct" parallelism & concurrency abstractions (threads, events, actors, channels, and so on) for our software and runtimes, it is helpful to step back and take a closer look at the actual hardware and where it is heading.
Moore's Law marches on, the transistor counts are continuing to increase at the predicted rate and will continue to do so for the foreseeable future. However, what has changed is where these transistors are going: instead of a single core, they are appearing in multi-core designs, which place a much higher premium on hardware and software parallelism. This is hardly news, I know. However, before we get back to arguing about the "correct" parallelism & concurrency abstractions (threads, events, actors, channels, and so on) for our software and runtimes, it is helpful to step back and take a closer look at the actual hardware and where it is heading.
Single Core Architecture & Optimizations
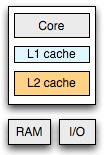 The conceptual architecture of a single core system is deceivingly simple: single CPU, which is connected to a block of memory and a collection of other I/O devices. Turns out, simple is not practical. Even with modern architectures, the latency of a main memory reference (~100ns roundtrip) is prohibitively high, which combined with highly unpredictable control flow has led CPU manufacturers to introduce multi-level caches directly onto the chip: Level 1 (L1) cache reference: ~0.5 ns; Level 2 (L2) cache reference: ~7ns, and so on.
The conceptual architecture of a single core system is deceivingly simple: single CPU, which is connected to a block of memory and a collection of other I/O devices. Turns out, simple is not practical. Even with modern architectures, the latency of a main memory reference (~100ns roundtrip) is prohibitively high, which combined with highly unpredictable control flow has led CPU manufacturers to introduce multi-level caches directly onto the chip: Level 1 (L1) cache reference: ~0.5 ns; Level 2 (L2) cache reference: ~7ns, and so on.
However, even that is not enough. To keep the CPU busy, most manufacturers have also introduced some cache prefetching and management schemes (ex: Intel's SmartCache), as well as invested billions of dollars into branch prediction, instruction pipelining, and other tricks to squeeze every ounce of performance. After all, if the CPU has a separate floating point and an integer unit, then there is no reason why two threads of execution could not simultaneously run on the same chip - see SMT. Remember Intel's Hyperthreading? As another point of reference, Sun's Niagara chips are designed to run four execution threads per core.
But wait, how did threads get in here? Turns out, threads are a way to expose the potential (and desired) hardware parallelism to the rest of the system. Put another way, threads are a low-level hardware and operating system feature, which we need to take full advantage of the underlying capabilities of our hardware.
Architecting for the Multi-core World
Since the manufacturers could no longer continue scaling the single core (power, density, communication), the designs have shifted to the next logical architecture: multiple cores on a single chip. After all, hardware parallelism existed all along, so the conceptual shift wasn't that large - shared memory, multiple cores, more concurrent threads of execution. Only one gotcha, remember those L1, L2 caches we introduced earlier? Turns out, they may well be the Achilles' heel for multi-core.
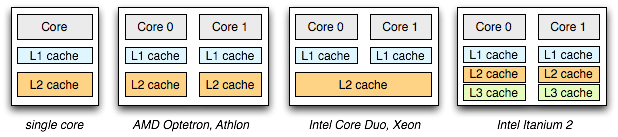
If you were to design a multi-core chip, would you allow your cores to share the L1, or L2 cache, or should they all be independent? Unfortunately, there is one answer to this question. Shared caches can allow higher utilization, which may lead to power savings (ex: great for laptops), as well as higher hit rates in certain scenarios. However, that same shared cache can easily create resource contention if one is not careful (DMA is a known offender). Intel's Core Duo and Xeon processors use a shared L2, whereas AMD's Opteron, Athlon, and Intel's Pentium D opted out for independent L1's and L2's. Even more interestingly, Intel's recent Itanium 2 gives each core an independent L1, L2, and an L3 cache! Different workloads benefit from different layouts.
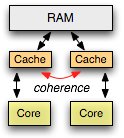 As Phil Karlton once famously said: "There are only two hard things in Computer Science: cache invalidation and naming things," and as someone cleverly added later, "and off by one errors". Turns out, cache coherency is a major problem for all multi-core systems: if we prefetch the same block of data into an L1, L2, or L3 of each core, and one of the cores happens to make a modification to its cache, then we have a problem - the data is now in an inconsistent state across the different cores. We can't afford to go back to main memory to verify if the data is valid on each reference (as that would defeat the purpose of the cache), and a shared mutex is the very anti-pattern of independent caches!
As Phil Karlton once famously said: "There are only two hard things in Computer Science: cache invalidation and naming things," and as someone cleverly added later, "and off by one errors". Turns out, cache coherency is a major problem for all multi-core systems: if we prefetch the same block of data into an L1, L2, or L3 of each core, and one of the cores happens to make a modification to its cache, then we have a problem - the data is now in an inconsistent state across the different cores. We can't afford to go back to main memory to verify if the data is valid on each reference (as that would defeat the purpose of the cache), and a shared mutex is the very anti-pattern of independent caches!
To address this problem, hardware designers have iterated over a number of data invalidation and propagation schemes, but the key point is simple: the cores share a bus or an interconnect over which messages are propagated to keep all of the caches in sync (coherent), and therein lies the problem. While, the numbers vary, the overall consensus is that after approximately 32 cores on a single chip, the amount of required communication to support the shared memory model leads to diminished performance. Put another way, shared memory systems have limited scalability.
Turtles all the way down: Distributed Memory
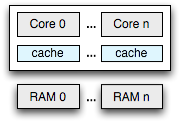 So if cache coherence puts an upper bound on the number of cores we can support within the shared memory model, then lets drop the shared memory requirement! What if, instead of a monolithic view of the memory, each core instead had its own, albeit much smaller main memory? Distributed memory model has the advantage of avoiding all of the cache coherency problems we listed above. However, it is also easy to imagine a number of workloads where the distributed memory will underperform the shared memory model.
So if cache coherence puts an upper bound on the number of cores we can support within the shared memory model, then lets drop the shared memory requirement! What if, instead of a monolithic view of the memory, each core instead had its own, albeit much smaller main memory? Distributed memory model has the advantage of avoiding all of the cache coherency problems we listed above. However, it is also easy to imagine a number of workloads where the distributed memory will underperform the shared memory model.
There doesn't appear to be any consensus in the industry yet, but if one had to guess, then a hybrid model seems likely: push the shared memory model as far as you can, and then stamp it out multiple times on a chip, with a distributed memory interconnect - it is cache and interconnect turtles all the way down. In other words, while message passing may be a choice today, in the future, it may well be a requirement if we want to extract the full capabilities of the hardware.
Turtles all the way up: Web Architecture
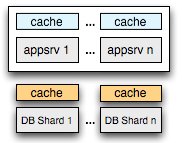 Most interesting of all, we can find the exact same architecture patterns and their associated problems in the web world. We start with a single machine running the app server and the database (CPU and main memory), which we later split into separate instances (multiple app servers share a remote DB, aka 'multi-core'), and eventually we shard the database (distributed memory) to achieve the required throughput. The similarity of the challenges and the approaches seems hardly like a coincidence. It is turtles all the way down, and it is turtles all the way up.
Most interesting of all, we can find the exact same architecture patterns and their associated problems in the web world. We start with a single machine running the app server and the database (CPU and main memory), which we later split into separate instances (multiple app servers share a remote DB, aka 'multi-core'), and eventually we shard the database (distributed memory) to achieve the required throughput. The similarity of the challenges and the approaches seems hardly like a coincidence. It is turtles all the way down, and it is turtles all the way up.
Threads, Events & Message Passing
As software developers, we are all intimately familiar with the shared memory model and the good news is: it is not going anywhere. However, as the core counts continue to increase, it is also very likely that we will quickly hit diminishing returns with the existing shared memory model. So, while we may disagree on whether threads are a correct application level API (see process calculi variants), they are also not going anywhere - either the VM, the language designer, or you yourself will have to deal with them.
With that in mind, the more interesting question to explore is not which abstraction is "correct" or "more performant" (one can always craft an optimized workload), but rather how do we make all of these paradigms work together, in a context of a simple programming model? We need threads, we need events, and we need message passing - it is not a question of which is better.
 Ilya Grigorik is a web ecosystem engineer, author of High Performance Browser Networking (O'Reilly), and Principal Engineer at Shopify — follow on Twitter.
Ilya Grigorik is a web ecosystem engineer, author of High Performance Browser Networking (O'Reilly), and Principal Engineer at Shopify — follow on Twitter.