Distributed Coordination with Zookeeper
 The Apache Hadoop project is an umbrella for a number of sub-projects, many of which are quite useful outside the Hadoop framework itself. Avro, for one, is a serialization framework with great performance and an API tailored for dynamic environments. Likewise, Zookeeper is a project incubated within the Hadoop ecosystem, but worth spending some time with due its wide applicability for building distributed systems.
The Apache Hadoop project is an umbrella for a number of sub-projects, many of which are quite useful outside the Hadoop framework itself. Avro, for one, is a serialization framework with great performance and an API tailored for dynamic environments. Likewise, Zookeeper is a project incubated within the Hadoop ecosystem, but worth spending some time with due its wide applicability for building distributed systems.
Back in 2006, Google published a paper on "Chubby", a distributed lock service which gained wide adoption within their data centers. Zookeeper, not surprisingly, is a close clone of Chubby designed to fulfill many of the same roles for HDFS and other Hadoop infrastructure. The original paper from Google offers a number of interesting insights, but the biggest takeaway is: Chubby and Zookeeper are both much more than a distributed lock service. In fact, it may be better to think of them as implementations of highly available, distributed metadata filesystems.
Zookeeper as a Metadata Filesystem
At its core, Zookeeper is modeled after a straightforward, tree based, file system API. A client is able to create a node, store up to 1MB of data with it, and also associate as many children nodes as they wish. However, there are no renames, soft or hard links, and no append semantics. Instead, by dropping those features, Zookeeper guarantees completely ordered updates, data versioning, conditional updates (CAS), as well as, a few more advanced features such as "ephemeral nodes", "generated names", and an async notification ("watch") API.
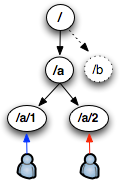 Now, this may seem like a grab bag of features, but don't forget that all of this is functionality is exposed as a remote service. Meaning, any network client can create a node, update associated metadata, submit a conditional update, or request an async notification via a "watch" request, which essentially mirrors the inotify functionality exposed in the Linux kernel.
Now, this may seem like a grab bag of features, but don't forget that all of this is functionality is exposed as a remote service. Meaning, any network client can create a node, update associated metadata, submit a conditional update, or request an async notification via a "watch" request, which essentially mirrors the inotify functionality exposed in the Linux kernel.
Likewise, to make things easier, a client can request for Zookeeper to generate the node name to avoid collisions (e.g. to allow multiple concurrent clients to create nodes within same namespace without any collisions). And last but not least, what if you wanted to create a node, which only existed for the lifetime of your connection to Zookeper? That's what "ephemeral nodes" are for - essentially, they give you presence. Now, put all of these things together, and you have a powerful toolkit to solve many problems in distributed computing.
Zookeeper: Distributed Architecture
Of course, if we are to deploy Zookeeper in a distributed environment, we have to think about both the availability and scalability of the service. At Google, Chubby runs on a minimum of five machines, to guarantee high availability, and also transparently provides a built-in master election and failover mechanisms. Not surprisingly, Zookeeper is built under the same model.
Given a cluster of Zookeeper servers, only one acts as a leader, whose role is to accept and coordinate all writes (via a quorum). All other servers are direct, read-only replicas of the master. This way, if the master goes down, any other server can pick up the slack and immediately continue serving requests. As an interesting sidenote, Zookeeper allows the standby servers to serve reads, whereas Google's Chubby directs all reads and writes to the single master - apparently a single server can handle all the load!
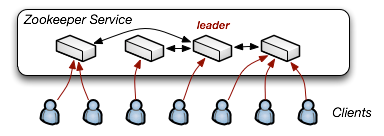
The one limitation of this design is that every node in the cluster is an exact replica - there is no sharding and hence the capacity of the service is limited by the size of an individual machine. The Google paper briefly mentions a possible logical sharding scheme, but in practice, it seems that they had no need for such a feature just yet. Now let's take a look at the applications.
Applications on top of Zookeeper & Chubby
Within the Hadoop/HBase umbrella, Zookeeper is used to manage master election and store other process metadata. Hadoop/HBase competitors love to point to Zookeeper as a SPOF (single point of failure), but in reality, given the backing architecture this seems to be too often over-dramatized. Perhaps even more interestingly, as the Google paper mentions, Chubby has in effect replaced DNS within the Google infrastructure!
 By allowing any client to access and store metadata, you can imagine a simple case where a cluster of databases can share their configuration information (sharding functions, system configs, etc), within a single namespace:
By allowing any client to access and store metadata, you can imagine a simple case where a cluster of databases can share their configuration information (sharding functions, system configs, etc), within a single namespace: /app/database/config. In fact, each database could request a watch on that node, and receive real-time notifications whenever someone updates the data (for example, a data rebalancing due to adding a new database into the cluster).
However, that is just the beginning. Since "ephemeral nodes" provide basic presence information, by having each worker machine register with Zookeeper, we can perform real-time group membership queries to see which nodes are online, and perhaps even figure out what they are currently doing.
What about consensus? With a little extra work we can also leverage the data versioning and notifications APIs to build distributed primitives such as worker queues and barriers. From there, once we have locks and consensus, we can tackle virtually any distributed problem: master election, quorum commits, and so on. In other words, it becomes your swiss army knife for coordinating distributed services.
Working with Zookeeper
Getting started with Zookeeper is relatively straightforward: download the source, load the jar file, and you're ready to experiment in a single node mode. From there, you can try interacting with Zookeeper via a simple shell provided with the project:
# create root node for an application, with world read-write permissions
[zk: localhost:2181(CONNECTED) 2] create /myapp description world:anyone:cdrw
#Created /myapp
# Create a sequential (-s) and ephemeral (-e) node
[zk: localhost:2181(CONNECTED) 6] create -s -e /myapp/server- appserver world:anyone:cdrw
#Created /myapp/server-0000000001
# List current nodes
[zk: localhost:2181(CONNECTED) 5] ls /myapp
# [server-0000000000]
# Fetch data for one of the nodes
[zk: localhost:2181(CONNECTED) 8] get /myapp/server-0000000001
# appserverzookeeper - Mirror of Apache Hadoop ZooKeeper
Similarly, we can perform all of the same actions directly from Ruby via several libraries. The zookeeper_client gem provides bindings against the C-based API, but unfortunately it doesn't support some of the more advanced features such as watches and asynchronous notifications. Alternatively, the zookeeper gem by Shane Mingins provides a fully featured JRuby version, which seems to cover the entire API.
And if you are feeling adventurous, you could even try the experimental FUSE mount, or the REST server for Zookeeper. For some ideas, check out game_warden (Ruby DSL for dynamic configuration management) built around zookeeper, and a few other articles on the project. Zookeeper is already in use in a number of projects and companies (Digg, LinkedIn, Wall Street), so you are in good company.
 Ilya Grigorik is a web ecosystem engineer, author of High Performance Browser Networking (O'Reilly), and Principal Engineer at Shopify — follow on Twitter.
Ilya Grigorik is a web ecosystem engineer, author of High Performance Browser Networking (O'Reilly), and Principal Engineer at Shopify — follow on Twitter.