Cluster Monitoring with Ganglia & Ruby
 A good monitoring solution can make or break an entire service - a well implemented one will enable you to forecast and plan ahead, as well as, quickly spot and debug problems when they arise. However, anyone that has worked with a cluster of machines will know that this is also a non-trivial problem. There are a number of options, both open-source and commercial, and they span a variety of use cases: alerting and notification (Nagios), intrusion detection (SNORT), performance monitoring (Ganglia, Cacti, Scout, etc), or even customized systems such as MySQL Monitor for in-depth database analysis.
A good monitoring solution can make or break an entire service - a well implemented one will enable you to forecast and plan ahead, as well as, quickly spot and debug problems when they arise. However, anyone that has worked with a cluster of machines will know that this is also a non-trivial problem. There are a number of options, both open-source and commercial, and they span a variety of use cases: alerting and notification (Nagios), intrusion detection (SNORT), performance monitoring (Ganglia, Cacti, Scout, etc), or even customized systems such as MySQL Monitor for in-depth database analysis.
Chances are, you will have to run a mix of all of the above to cover all the cases (ex: WikiMedia's Nagios & Ganglia) since there is no all-in-one solution and each has its tradeoffs. On that note, for performance monitoring, Ganglia is definitely an option to explore (it seems that I tried everything but Ganglia first, and I wish I did so much earlier). Originally developed at University of California, it is an open-source project designed from the ground up to be a distributed monitoring system for high-performance system such as clusters and grids - let's see what that means.

Ganglia's Distributed Architecture
Ganglia is powered by three independent components: gmond, gmetad and a PHP frontend. Due to how the system is architected, all three could either run on the same host, or more likely, be distributed between a number of different nodes. Gmond is the workhorse responsible for gathering user specified stats and sharing them over the network: a gmond daemon runs on every monitored node. It is designed to be fast, portable, with low memory footprint, and comes with a number of native monitoring modules (disk, memory, network, etc).
Importantly, the gmond daemon never actually persists any data (memory only) to optimize for speed. But that's not all, because it can also receive data from other gmond's, allowing us to build arbitrary hierarchies of nodes - this is how and why Ganglia is capable of scaling to thousands of nodes.
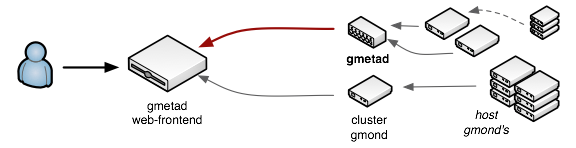
Unlike other monitoring solutions such as Nagios or Cacti, all of the Ganglia metrics rely on data push - there is absolutely no polling involved. The gmond daemons are all responsible for periodically gathering and distributing their stats upstream. However, the gmond's do not persist data, and that is where the gmetad daemon comes in.
This daemon is responsible for collecting data from an arbitrary number of gmond's, or even other gmetad daemons, persisting the metrics into correct RRD (round robin database) files, and then making this data available to the PHP frontend (or any other service that consumes RRD's).
Distributed Monitoring & Custom Metrics
 Wikimedia's Ganglia setup is a good example to dissect: it consists of two "clusters" (Florida and Kennisnet), each most likely running their own gmetad node, which is then monitored by a central gmetad node which stitches them together. Each cluster, in turn, has its own hierarchy of gmond nodes: squids, apaches, databases, and so on. All together, it is monitoring over 350 nodes without breaking a sweat - not bad. Alas, one gotcha to be aware of upfront: run your gmetad's off a ram-disk to avoid the IO bottleneck associated with updating hundreds of RRD's.
Wikimedia's Ganglia setup is a good example to dissect: it consists of two "clusters" (Florida and Kennisnet), each most likely running their own gmetad node, which is then monitored by a central gmetad node which stitches them together. Each cluster, in turn, has its own hierarchy of gmond nodes: squids, apaches, databases, and so on. All together, it is monitoring over 350 nodes without breaking a sweat - not bad. Alas, one gotcha to be aware of upfront: run your gmetad's off a ram-disk to avoid the IO bottleneck associated with updating hundreds of RRD's.
With default configuration the gmond daemon will automatically monitor over 20 core metrics: load, network in and out, disk, memory and so on. However, it is also easily extensible via several mechanisms: custom monitoring modules, or straight up gmetric command line client. As of version 3.1.0, Ganglia now offers a simple Python API which allows us to create custom metrics modules which will be integrated directly into the gmond process. Hence the gmond process will call the code, gather the metrics and then distribute the data for us. A great working example is Gilad Raphaelli's MySQL extension, which gathers over 50 metrics about your database, and creating your own is also pretty straightforward.
However, if writing a python script is too heavy weight, Ganglia also provides the 'gmetric' executable which you can call right from the command line. Give the metric a name, type and a value, and you are off to the races. In other words, you can use bash, Ruby, or anything that will execute from the command line, in combination with gmetric, to funnel data into Ganglia:
# submit "variable_name" which is a string, with value of "hello", remove this var after 600s
$ gmetric -n variable_name -t string -v "hello" -d 600
# submit "int_var", which is an 8-bit int, with value of 20, remove this var after 60s
$ gmetric -n int_var -t uint8 -v 20 -d 60Connecting Ganglia With Ruby
One of the key advantages of Ganglia over Cacti or similar services is that there is no per variable data source setup. Once a metric is pushed to a gmetad node, it automatically gets its own RRD file, and appears on your dashboard - no configuration required, just bring up a new service, push the data and you're rocking!
Now, if you want to monitor a Ruby process, you have a couple of alternatives: write a python module, or shell out to gmetric. Neither is optimal because while the first method requires more (Python) code and extra polling, the system exec option can also be prohibitively expensive in terms of performance. Thankfully, Ganglia uses a simple UDP protocol with XDR data formatting which means that with a little reverse-engineering, we can talk to our gmond process directly from Ruby (by pretending that it is gmetric generating the packets):
require 'gmetric'
# generate metric from Ruby and send it over UDP
Ganglia::GMetric.send("127.0.0.1", 8670, {
:name => 'pageviews',
:units => 'req/min',
:type => 'uint16', # unsigned 8-bit int
:value => 7000, # value of metric
:tmax => 60, # maximum time in seconds between gmetric calls
:dmax => 300 # lifetime in seconds of this metric
})gmetric - GMetric Ruby Library
Install the gmetric gem, specify the hostname and port number of your gmond daemon and fire off your metrics via UDP directly into the monitoring system. This way, you can track latency, request rates, throughput, or any other application metric directly from Ruby and push it into Ganglia without any performance penalties.
Finally, once you have pushed a dozen new metrics, you can then also generate your own cumulative reports, which aggregate data from multiple sources (key database metrics, etc). Ganglia is an incredibly flexible platform, and the 3.1.x release has done a lot to improve the ability to customize and extend it to fit your applications. If you haven't already, definitely a tool to look into for your cloud applications.
 Ilya Grigorik is a web ecosystem engineer, author of High Performance Browser Networking (O'Reilly), and Principal Engineer at Shopify — follow on Twitter.
Ilya Grigorik is a web ecosystem engineer, author of High Performance Browser Networking (O'Reilly), and Principal Engineer at Shopify — follow on Twitter.