Collaborative / Swarm Computing Notes
 If you were looking for a great example of a collaborative map-reduce, then you don't have look much further than the amount of feedback and commentary that the earlier 'Collaborative Map-Reduce in the Browser' post received in a short span of twenty four hours. After making appearances on Slashdot, dozens of blogs, podcasts, and numerous social networks, it generated over four hundred comments, suggestions and critiques. Seemingly out of thin air, an intelligent swarm self-assembled, where none existed before, went through a highly creative phase of idea generation and critique, and then disappeared as fast as it came together, leaving a wealth of ideas to research and follow up on.
If you were looking for a great example of a collaborative map-reduce, then you don't have look much further than the amount of feedback and commentary that the earlier 'Collaborative Map-Reduce in the Browser' post received in a short span of twenty four hours. After making appearances on Slashdot, dozens of blogs, podcasts, and numerous social networks, it generated over four hundred comments, suggestions and critiques. Seemingly out of thin air, an intelligent swarm self-assembled, where none existed before, went through a highly creative phase of idea generation and critique, and then disappeared as fast as it came together, leaving a wealth of ideas to research and follow up on.
Observing this pattern made me wonder about the future of science, and how radically different it is from the current ivory tower approach of life-long research tracks, specialized conferences, and tight knit groups. But that's a subject for another discussion, and on that note, below is a summary of the common themes and some of the most interesting comments generated by the community. I apologize upfront if I omitted anybody's name or did not attribute ideas to the right source.
Read original post on Collaborative Map-Reduce in the Browser
Existing and Alternative Solutions
Numerous people have provided links to alternative or similar implementations of massively distributed computation models. The BOINC open-source project is probably the most notable one in this pace, with over 500,000 participants, albeit it does require a standalone client. There also appears to be several commercial initiatives in this space: 80legs.com is a distributed crawler with approximately 50,000 nodes, and pluraprocessing.com is using the browser model and the JVM for client-side computation. In fact, there also appears to be a patent which describes the browser based model (USPTO: 20020198932).
 On a much less serious but thought provoking note, a number of people have pointed out that Google may not be far behind in this initiative either. As Jesse Andrews writes: "I suspect Google is testing their grid by having Macs compute pi to hundreds of digits. If results are positive, G2C2 (Global Google Compute Cluster) will be activated for everyone... Avril Lavigne - Girlfriend's 116 million views could have contributed 838 years of compute time." In this light, Google's Native Client (video tech talk), and Google Gears are certainly heading in the right direction.
On a much less serious but thought provoking note, a number of people have pointed out that Google may not be far behind in this initiative either. As Jesse Andrews writes: "I suspect Google is testing their grid by having Macs compute pi to hundreds of digits. If results are positive, G2C2 (Global Google Compute Cluster) will be activated for everyone... Avril Lavigne - Girlfriend's 116 million views could have contributed 838 years of compute time." In this light, Google's Native Client (video tech talk), and Google Gears are certainly heading in the right direction.
Scalability and Performance
Not surprisingly, the subject of performance and scalability generated a lot of conversation. First, there is the question of the job server as a single point of failure, and the non-stateful nature of the HTTP protocol which introduces the need for a storage layer not unlike the Amazon S3. However, while definitely a technical challenge, it is not outside of the realm of the already well-established tools and techniques: load balancing, geo-distribution, and cloud storage. In fact, many of these problems have already been addressed by the P2P community, with protocols such as BitTorrent), and Distributed Hash Tables (DHT).
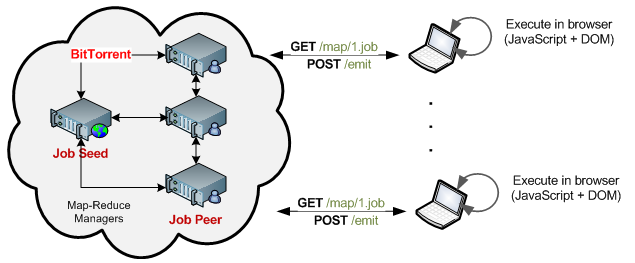
Then there is the question of Javascript as a language of choice. While hardly a speed-demon, it is the wide availability of it (browsers, mobile devices, etc) and the extremely low barrier to entry (clicking on a URL) that make it such an interesting choice. In fact, instead of thinking of the web as a single-purpose compute cluster, it opens a different method of thinking: ad-hoc compute clusters (swarms of computers) which can descend on a problem, contribute thousands of CPU hours in a matter of minutes, and then vanish a few seconds later. Dare I say, Swarm Computing?
Some great comments and responses from the community:
Javascript really isn't suited for this kind of thing, even with worker threads, for two reasons I can think of. First, web clients are transient... they'd have to report back often in case the user clicks away. But more importantly, Javascript just isn't a good language for massive computation. It only supports one kind of number (double), has no vectorization or multicore capabilities, has no unboxed arrays, and even for basically scalar code is some 40x slower than C, let alone optimized ASM compute kernels.
You are significantly underutilizing the clients' but it makes it very easy, unto attractive, to get clients. Make it attractive and trivial to contribute processing time - ANY processing time - and the computational power available quickly becomes staggering. Making efficient use of it is an ongoing matter of tweaking & improvements, far less important than getting the donated power in the first place.
And you don't think you could get 100 times more users to visit your web app than you could convince to download and install an exe?"
I think you are vastly underestimating the JIT engines of Chrome and FF. While these JIT engines still have a way to go, I would expect the execution speed of Javascript to approach the performance of other modern virtual machines like the JVM."
The speed difference is absolutely irrelevant. We are not talking about substituting this for natively run code, we are talking about reaching a different demographic. If the code is not run this way that doesn’t mean it will be run in C, it means that it will not be run at all.
Mix it with worker threads and people wouldn’t even have to know that they were doing computational work. It could just run quietly in the background.
Security and Trust
For any security professional, the thought of executing arbitrary code in the browser is their worst nightmare (XSS, injection attacks, etc). Fortunately, Google Chrome & Native Client projects, and Microsoft's Gazelle are already tackling the browser security questions head on. Likewise, many of the other concerns have their parallels in existing products and applications:
- How can you trust the client's output? You don't! SETI@Home distributes same workload to a number of random clients, and then uses a quorum voting approach to ensure the correctness.
- How can you trust the provider? Establish a trusted third party to validate the provider, or, as Mischa has cleverly pointed out: "There would have to be some sort of ratings / popularity so that it would be obvious which projects were worth it / not evil."
Business Models and Applications
Perhaps not surprisingly, the question of economics and associated business models generated a mountain of innovative ideas. In fact, after some reflection, it is surprising to realize that in a world where we've arbitraged every conceivable asset, we don't yet have a market for the idle CPU power! Surely that's a business waiting to happen.
Another idea could be to use a Google Adwords / Adsense approach whereby instead of serving up a Google text ad on your blog or website, participating websites could serve up a distributed batch job at the same cost as an ad click-through. The costs could be managed in a similar Google adwords like interface where users could determine how much they are prepared to spend on their map/reduce jobs."
If there were a couple-few or more orgs competing to use my extra cycles, outbidding each other with money in my account buying my cycles, I might trust them to control those extra cycles. If they sold time on their distributed supercomputer, they'd have money to pay me. As a variation, I wouldn't be surprised to see Google distribute its own computing load onto the browsers creating that load. Though both models raise the question of how to protect that distributed computing from being attacked by someone hostile, poisoning the results to damage the central controller's value from it (or its core business)"
Here are some more "business ideas" for your enjoyment: Buy tons of those fancy interactive visual advertisements, embed the worker into them and perform mapreduce jobs in the browsers of unsuspecting users. Run some of the analytic/batch processing related to a popular social network on CPUs of your customers. Have a popular site? Sell CPUs of its audience just like one sells impressions via AdSense."
Bloggers and social networkers could leverage their reach to help cure cancer. Laughing Squid could embed a wrapped youtube player that folds protein in the background.
And if that's not enough, Philipp Lansen of blogoscoped.com fame, asks a question worth thinking about: "Could this approach be combined with some Mechanical Turk/ CHI style machine to solve tasks not easily programmed?". A quick twitter poll later, and yes, computer vision, pattern recognition, and NLP are all notoriously hard problems for a computer, which are often easily solved by a human. Perhaps it is the combination of the low barrier to entry with the browser, idle CPU's, and an army of Mechanical Turks that will bring us the next supercomputer.
 Ilya Grigorik is a web ecosystem engineer, author of High Performance Browser Networking (O'Reilly), and Principal Engineer at Shopify — follow on Twitter.
Ilya Grigorik is a web ecosystem engineer, author of High Performance Browser Networking (O'Reilly), and Principal Engineer at Shopify — follow on Twitter.