Ruby 1.9 Internals: Ordered Hash
 With the first stable release of Ruby 1.9 out the door (1.9.1) it is time to start thinking about migrating your code to the newer runtime. Performance is much improved, and plenty of new features are waiting to be taken advantage of. One of these is the new ordered Hash which unlike Ruby 1.8.x preserves the insertion order:
With the first stable release of Ruby 1.9 out the door (1.9.1) it is time to start thinking about migrating your code to the newer runtime. Performance is much improved, and plenty of new features are waiting to be taken advantage of. One of these is the new ordered Hash which unlike Ruby 1.8.x preserves the insertion order:
# Ruby 1.8.7
irb(main):001:0> {:a=>"a", :c=>"c", :b=>"b"}
=> {:a=>"a", :b=>"b", :c=>"c"}
# Ruby 1.9.1 (in insertion order)
irb(main):001:0> {:a=>"a", :c=>"c", :b=>"b"}
=> {:a=>"a", :c=>"c", :b=>"b"}Of course, the question you're asking is, how does it do that? What about performance? Let's take a look inside.
The C behind the Ruby
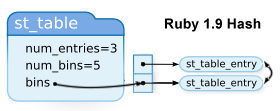 For a good, albeit incomplete and now somewhat outdated primer on Ruby internals, make sure to read through the Ruby Hacking Guide (I hope we'll get a full English version for Ruby 1.9). The source code reveals that the data layer of a Ruby Hash is, in fact encapsulated in a st_table struct, which in turn, links to a collection of pointers to st_table_entry objects which are the actual values. Add a hashing function on top and you've got yourself a Ruby 1.8 Hash.
For a good, albeit incomplete and now somewhat outdated primer on Ruby internals, make sure to read through the Ruby Hacking Guide (I hope we'll get a full English version for Ruby 1.9). The source code reveals that the data layer of a Ruby Hash is, in fact encapsulated in a st_table struct, which in turn, links to a collection of pointers to st_table_entry objects which are the actual values. Add a hashing function on top and you've got yourself a Ruby 1.8 Hash.
However, this structure also has no notion of order, which means that a separate structure has to be created if the property is needed in your application - duplicating memory, and adding overhead overall. For that reason, if you've ever used the Facets Dictionary class, you would have noticed that it simply creates an adjacent array for the keys (every insert pushes the key on top of the stack). It's dirty, but it works. What about Ruby 1.9?

It turns out in Ruby 1.9, a Hash is also a doubly-circular linked list! Every st_table_entry now contains two pointers for moving forwards and backwards in the list. Hence, aside from the pointer manipulation, no other overhead is incurred:
// Ruby 1.9 internal hash entry struct
struct st_table_entry {
unsigned int hash;
st_data_t key;
st_data_t record;
st_table_entry *next;
st_table_entry *fore, *back; // new in Ruby 1.9
};Hash performance in 1.8 and 1.9
Ruby mailing list archive is full of heated discussions on whether a Ruby hash should be an ordered hash: simplicity vs performance vs least surprise. And strictly speaking, the new Ruby Hash is slower, because deletion and insertion requires more pointer manipulation. However, value fetch has not changed, and traversal is now much faster (since we can just follow the pointers):
# Ruby 1.8.7 user system total real
Hash insert 0.350 0.610 0.960 ( 0.990365)
Hash access 0.770 0.010 0.780 ( 0.801897)
Dict insert 1.000 1.240 2.240 ( 2.333807)
Dict access 1.100 0.020 1.120 ( 1.304059)
RBTree insert 4.820 1.000 5.820 ( 6.293545)
RBTree access 5.180 0.110 5.290 ( 6.060176)
# Ruby 1.9.1 user system total real
Hash insert 0.650 0.150 0.800 ( 0.828039)
Hash access 0.650 0.000 0.650 ( 0.683463)The performance numbers are slightly obscured by the fact that the Ruby 1.9 interpreter is faster to begin with, so we can't attribute the performance gains to Hash implementation alone, but I think it highlights the fact that the right decision was made: more powerful Hash in 1.9, faster.
Red-Black Trees
One interesting alternative to consider is a Red-black tree, which is a data structure commonly used to maintain associative arrays with a nice property of O(log n) access time for all operations. Unlike a simple binary tree, a red-black tree introduces additional constraints which force it to be a balanced tree after every operation - meaning, there are no worst case scenarios as you get in a binary tree. It is a nontrivial structure, but thankfully it's also available as a Ruby 1.8 gem: rbtree.
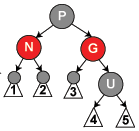 Due to the nice access properties, Red-black tree powers the default ("completely fair") scheduler in the Linux 2.6.23 kernel. It turns out, the extra overhead of maintaining a tree is well compensated for large tasksets, where the O(log n) runtime really delivers.
Due to the nice access properties, Red-black tree powers the default ("completely fair") scheduler in the Linux 2.6.23 kernel. It turns out, the extra overhead of maintaining a tree is well compensated for large tasksets, where the O(log n) runtime really delivers.
Unfortunately rbtree is not yet 1.9 compatible, but it is definitely worth a look as in certain cases it may be far better suited than a simple Hash.
 Ilya Grigorik is a web ecosystem engineer, author of High Performance Browser Networking (O'Reilly), and Principal Engineer at Shopify — follow on Twitter.
Ilya Grigorik is a web ecosystem engineer, author of High Performance Browser Networking (O'Reilly), and Principal Engineer at Shopify — follow on Twitter.