Zero-Downtime Restarts with HAProxy

Putting up a maintenance page while you are doing an update and restarting your application servers is good practice, but it definitely hurts the user experience. This, in turn, translates to less frequent releases and frustration for both the developer and the users (release often, release early!). To address this, the Rails community has come up with a couple of approaches to mitigate the problem: Seesaw, one-at-a-time restarts, and Swiftiply, none of which, unfortunately, caught on with the crowd. Well, it turns out, HAProxy has a beautiful solution for this problem!
Existing Solutions
The challenge with doing a rolling restart is in the coordination between your application servers, and an upstream reverse-balancer (HAProxy, Nginx, Apache, etc.). In theory, if you have a cluster of servers, you could cycle them one after another, as Carl has suggested, but that means that the upstream balancer is unaware of the maintenance window, and hence it may dispatch a request to a bad server - resulting in either a dropped request, or a hiccup in response time.
Swiftiply offers a much cleaner solution to this problem: each application server connects to the proxy itself, and thus the cluster can be dynamically modified at runtime. Great idea, but there is the unfortunate Ruby dependency - what if we're running a non Ruby service?
Seamless Restarts With HAProxy
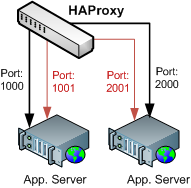 HAProxy architecture document shows that we can specify a backup for every application server in our cluster. Thus, if you're running a mission critical application, you could specify a hot standby which is ready to take over the traffic. Nice feature, but we're going to use it for a slightly different purpose.
HAProxy architecture document shows that we can specify a backup for every application server in our cluster. Thus, if you're running a mission critical application, you could specify a hot standby which is ready to take over the traffic. Nice feature, but we're going to use it for a slightly different purpose.
Instead of specifying a physically different app server, we're going to define our backup instance to be the exact same application server in each case, but with one minor difference: the status port, for the main app server will be different from the one we use on the backup.
backend srvs
# webA and webB are monitored on different ports from backup servers
# but bkpA, webA and bkpB and webB are actually the same server!
server webA 127.0.0.1:1000 check port 2000 inter 2000
server webB 127.0.0.1:1001 check port 2001 inter 2000
server bkpA 127.0.0.1:1000 cookie A check port 1000 inter 2000 backup
server bkpB 127.0.0.1:1001 cookie B check port 1001 inter 2000 backupUsing IPTables to Notify HAProxy
Let's take webA as an example: the backup server listens on port 1000, and status port for backup is set to 1000 (HAProxy pings the server on that port every two seconds to see if its up), but the 'main' instance will have a different status port, which we will forward with IPTables:
# forward port 2000 to 1000
$ iptables -t nat -A OUTPUT -p tcp --dport 2000 -j REDIRECT --to-port 1000
$ iptables -t nat -A PREROUTING -p tcp --dport 2000 -j REDIRECT --to-port 1000
# remove port forwarding from 2000 to 1000
$ iptables -t nat -D OUTPUT -p tcp --dport 2000 -j REDIRECT --to-port 1000
$ iptables -t nat -D PREROUTING -p tcp --dport 2000 -j REDIRECT --to-port 1000rolling-restart.zip - Test setup, and configuration files
Migrating Server In/Out of Maintenance
Now, if we want to put the server into maintenance mode, we remove the IPTables rule for the forwarded port, and wait a few seconds so that our upstream HAProxy instance recognizes that the server is no longer available for new connections - this is key, it means that no client is dropped in the process. Now, once the server is out of rotation in HAProxy, we can do a graceful restart, add the IPTables rule back in, and we're live! Hence, the full restart sequence is:
- Delete IPTables rule for the status port
- Wait for HAProxy to take server out of rotation for new clients
- Perform graceful restart of the application server
- Add IPTables rule for the status port
As an added bonus, you can even make this work with sticky sessions by adding a server ID into a cookie (see example HAProxy config in the zip). The clients won't notice a thing, and the developers can do zero-downtime releases!
 Ilya Grigorik is a web ecosystem engineer, author of High Performance Browser Networking (O'Reilly), and Principal Engineer at Shopify — follow on Twitter.
Ilya Grigorik is a web ecosystem engineer, author of High Performance Browser Networking (O'Reilly), and Principal Engineer at Shopify — follow on Twitter.