Thrudb - faster, cheaper than SimpleDB
 Amazon's recent announcement of SimpleDB generated a lot of buzz in the community - finally, a database service for our virtual infrastructure! Well, not so fast. SimpleDB is a far cry from the usual RDMBS we're all used to, and it's best described as a key-value store (BerkeleyDB, really), or a meta-data storage layer for your S3 objects. If you're curious, Charles Ying and Todd Hoff provide a great overview, as well as a plethora of links for more information on SimpleDB.
Amazon's recent announcement of SimpleDB generated a lot of buzz in the community - finally, a database service for our virtual infrastructure! Well, not so fast. SimpleDB is a far cry from the usual RDMBS we're all used to, and it's best described as a key-value store (BerkeleyDB, really), or a meta-data storage layer for your S3 objects. If you're curious, Charles Ying and Todd Hoff provide a great overview, as well as a plethora of links for more information on SimpleDB.
Document-oriented databases belong to a different paradigm and a realization that a run off the mill RDMBS is not a panacea to every problem. In many applications, all we need is a key lookup, ability to store and index massive amounts of data, and none of the other overhead that is associated with an RDMBS. SimpleDB, RDDB, and CouchDB all belong to this paradigm and offer very similar functionality.
However, there is also a new kid on the block, and boy does it look promising - Thrudoc. Developed by Jake Luciani as part of his ThruDB platform which currently powers JunkDepot, it is a highly scalable document-oriented database ideal for deployment on virtual (Amazon EC2+S3) or dedicated infrastructure.
Thrudb - looking under the hood
Thrudb is an attempt to simplify the management of the modern web data layer (indexing, caching, replication, backup) by providing a consistent set of services: Thrucene for indexing, Throxy for partitioning and load balancing, and Thrudoc for document storage. Jake's whitepaper provides a great overview of the design philosophy and API samples. In addition, the entire stack is implemented on top of Thrift, which allows for easy language interoperability and API access!
Thrudoc storage engines
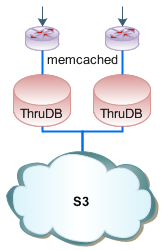
Thrudoc comes with several data storage engines: Disk, S3, and a yet undocumented (you heard it here first!) Disk+S3 backends. Each one is optimized for a different deployment scenario, so let's take a closer look:
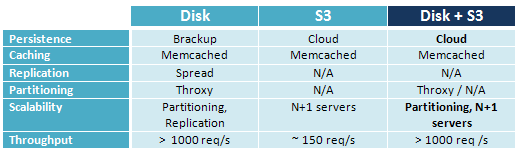
Disk based storage is arguably the most straight forward and offers a great set of services. By default, each document is assigned a UUID and stored as an individual file on the local filesystem. The contents of the document may be XML, JSON, a Thrift object, or even your own proprietary format - Thrudoc is data format agnostic and places no constraints on the size or type of data.
S3 based storage engine effectively turns the Thrudoc process into a proxy. All of the document data resides in the cloud, and hence you will never have to worry about disk-space constraints, data persistence or backup. Of course, due to the communications overhead with the S3 servers, the throughput of this system suffers (~150 req/s) as each request generates an S3 lookup or store. Having said that, the scaling can't be easier - just boot up more servers, they're all querying the same S3 bucket anyway! A load balancer, and N Thrudoc servers with S3 backend should provide the throughput capacity of N*150 req/s. Not bad, and we still have more tricks to increase performance! (Hint: memcached, see below)
Disk+S3 - one engine to rule them all
After some brainstorming, and a few late-night chats Jake created a Disk+S3 backend which gives us all the benefits of the Disk-only model, and the hassle free approach of the S3 engine. In this implementation, the data is persisted on local disk, which gives us an incredible throughput capacity, and a slave thread quietly replays all of the commands to the S3 backend as well, thus giving us a hassle free persistence and recovery model for virtual environments such as EC2! Let's take a look at the request cycles:
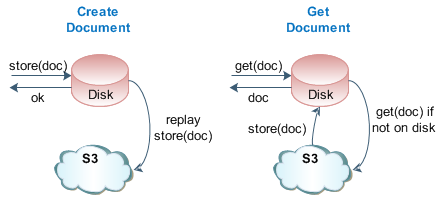
On every store, the data is persisted to disk, and a background process also replays the command to S3. You no longer have to worry about backups as your data is safe in the cloud even if the server goes down. However, while free backup is nice, the seamless recovery process is pure icing on the cake. If you look at the request cycle for a get query, you'll notice that disk is checked first, however, if the document is not found, Thrudoc issues a lookup command into the S3 cloud automagically! Once and if the document is found on S3, it is pulled into the disk storage and returned to the user - all subsequent lookups will find the file on disk.
You don't have to worry about recovering your data, simply bring up a fresh server and let the Thrudoc engine populate its index from S3 based on the current request profiles. Can't get much easier than that! To get started with Disk+S3 engine, open up thrudoc.conf, specify your S3 keys, your local index directory, and enable the engine:
BACKEND_TYPE = DISK+S3S3_BUCKET_NAME = thrudb AWS_ACCESS_KEY = XXXXXXXXXXXXXXXXXXXX AWS_SECRET_ACCESS_KEY = XXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXX THRUDB_ROOT = ../ DOC_ROOT = docs
Optional memcached layer for speed
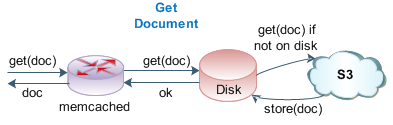
If speed and throughput are mission critical, there is an additional feature which every developer will love: Thrudoc is memcached aware. You can specify a local server or an array of memcached servers which will be positioned and queried before any request hits the Disk, S3, or Disk+S3 engines. Hence, as long as you have repeat queries, even the standalone S3 engine may provide more than enough throughput with memcached in front.
Indexing, search, and future of Thrudoc
In many ways Thrudoc is a direct competitor to Amazon's SimpleDB. The Disk+S3 engine provides hassle free setup, backup and recovery for deployment on EC2, and also removes many of the limitations inherent to SimpleDB - no 1024 byte limit per attribute, ability to use proprietary data formats, no query time limits, and more. However, some features are missing as well. Thrudoc is a strict document store system, and it has no native support for indexing, range queries, or meta-data lookups. Instead, these services are handled by Thrucene.
So is Thrudoc a replacement for SimpleDB? Perhaps, the two are sufficiently different to attract a different crowd and applications, but the upsides of a completely free, highly scalable system developed by Jake are going to be hard to overlook for many developers. One thing for sure, Thrudoc is a young but a very promising project and I hope that more developers will sign-on, spread the word, and contribute to the source!
 Ilya Grigorik is a web ecosystem engineer, author of High Performance Browser Networking (O'Reilly), and Principal Engineer at Shopify — follow on Twitter.
Ilya Grigorik is a web ecosystem engineer, author of High Performance Browser Networking (O'Reilly), and Principal Engineer at Shopify — follow on Twitter.