Collaborative Map-Reduce in the Browser
 After immersing yourself into the field of distributed computing and large data sets you inevitably come to appreciate the elegance of Google's Map-Reduce framework. Both the generality and the simplicity of its map, emit, and reduce phases is what makes it such a powerful tool. However, while Google has made the theory public, the underlying software implementation remains closed source and is arguably one of their biggest competitive advantages (GFS, BigTable, etc). Of course, there is a multitude of the open source variants (Apache Hadoop, Disco, Skynet, amongst many others), but one can't help but to notice the disconnect between the elegance and simplicity of the theory and the painful implementation: custom protocols, custom servers, file systems, redundancy, and the list goes on! Which begs the question, how do we lower the barrier?
After immersing yourself into the field of distributed computing and large data sets you inevitably come to appreciate the elegance of Google's Map-Reduce framework. Both the generality and the simplicity of its map, emit, and reduce phases is what makes it such a powerful tool. However, while Google has made the theory public, the underlying software implementation remains closed source and is arguably one of their biggest competitive advantages (GFS, BigTable, etc). Of course, there is a multitude of the open source variants (Apache Hadoop, Disco, Skynet, amongst many others), but one can't help but to notice the disconnect between the elegance and simplicity of the theory and the painful implementation: custom protocols, custom servers, file systems, redundancy, and the list goes on! Which begs the question, how do we lower the barrier?
Massively Collaborative Computation
After several iterations, false starts, and great conversations with Michael Nielsen, a flash of the obvious came: HTTP + Javascript! What if you could contribute to a computational (Map-Reduce) job by simply pointing your browser to a URL? Surely your social network wouldn't mind opening a background tab to help you crunch a dataset or two!
 Instead of focusing on high-throughput proprietary protocols and high-efficiency data planes to distribute and deliver the data, we could use battle tested solutions: HTTP and your favorite browser. It just so happens that there are more Javascript processors around the world (every browser can run it) than for any other language out there - a perfect data processing platform.
Instead of focusing on high-throughput proprietary protocols and high-efficiency data planes to distribute and deliver the data, we could use battle tested solutions: HTTP and your favorite browser. It just so happens that there are more Javascript processors around the world (every browser can run it) than for any other language out there - a perfect data processing platform.
Google's server farm is rumored to be over six digits (and growing fast), which is an astounding number of machines, but how hard would it be to assemble a million people to contribute a fraction of their compute time? I don't think it's far-fetched at all as long as the barrier to entry is low. Granted, the efficiency of the computation would be much lower, but we would have a much larger potential cluster, and this could enable us to solve a whole class of problems previously unachievable.
Client-Side Computation in the Browser
Aside from storing and distributing the data the most expensive part of any job is the CPU time. However, by splitting the data into small and manageable chunks, we could easily construct an HTTP-based workflow to let the user's browser handle this for us:
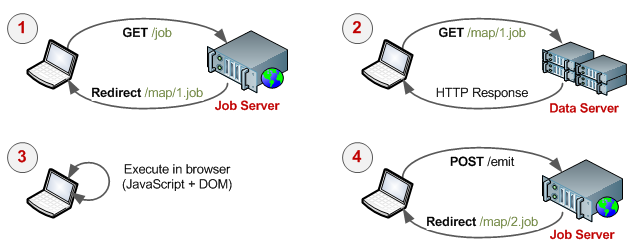
The entire process consists of four easy steps. First, the client requests to join the cluster by making a request to the job-server which tracks the progress of the computation. Next, the job-server allocates a unit of work and redirects (301 HTTP Redirect, for example) the client to a URL which contains the data and the Javascript map/reduce functions. Here is a sample for a simple distributed word-count:
<html>
<head>
<script type="text/javascript">
function map() {
/* count the number of words in the body of document */
var words = document.body.innerHTML.split(/\n|\s/).length;
emit('reduce', {'count': words});
}
function reduce() {
/* sum up all the word counts */
var sum = 0;
var docs = document.body.innerHTML.split(/\n/);
for each (num in docs) { sum+= parseInt(num) > 0 ? parseInt(num) : 0 }
emit('finalize', {'sum': sum});
}
function emit(phase, data) { ... }
</script>
</head>
<body onload="map();">
... DATA ...
</body>
</html>Once the page is loaded and the Javascript is executed (which is getting faster and faster with the Javascript VM wars), the results are sent back (POST) to the job-server, and the cycle repeats until all jobs (map and reduce) are done. Hence joining the cluster is as simple as opening a URL and distribution is handled by our battle-tested HTTP protocol.
Simple Job-Server in Ruby
The last missing piece of the puzzle is the job server to coordinate the distributed workflow. Which, as it turns out, takes just thirty lines of Ruby with the help of the Sinatra web framework:
require "rubygems"
require "sinatra"
configure do
set :map_jobs, Dir.glob("data/*.txt")
set :reduce_jobs, []
set :result, nil
end
get "/" do
redirect "/map/#{options.map_jobs.pop}" unless options.map_jobs.empty?
redirect "/reduce" unless options.reduce_jobs.empty?
redirect "/done"
end
get "/map/*" do erb :map, :file => params[:splat].first; end
get "/reduce" do erb :reduce, :data => options.reduce_jobs; end
get "/done" do erb :done, :answer => options.result; end
post "/emit/:phase" do
case params[:phase]
when "reduce" then
options.reduce_jobs.push params['count']
redirect "/"
when "finalize" then
options.result = params['sum']
redirect "/done"
end
end
# To run the job server:
# > ruby job-server.rb -p 80bmr-wordcount - Browser Map-Reduce: word-count example
That's it. Start up the server and type in the URL in your browser. The rest is both completely automated and easily parallelizable - just point more browsers at it! Add some load balancing, a database, and it may be just crazy enough that it might actually work.
Part II, with notes and commentary from the community: Collaborative / Swarm Computing Notes
 Ilya Grigorik is a web ecosystem engineer, author of High Performance Browser Networking (O'Reilly), and Principal Engineer at Shopify — follow on Twitter.
Ilya Grigorik is a web ecosystem engineer, author of High Performance Browser Networking (O'Reilly), and Principal Engineer at Shopify — follow on Twitter.